
POLAR BUBBLES
Today’s news, in 4 flavours - an experiment on media manipulation. news.cunicode.com
Polar Bubbles explores how filter bubbles, polarization, and echo chambers affect modern media. It looks at personalized algorithms and information networks, showing how ideological isolation impacts public discussions.
news.cunicode.com

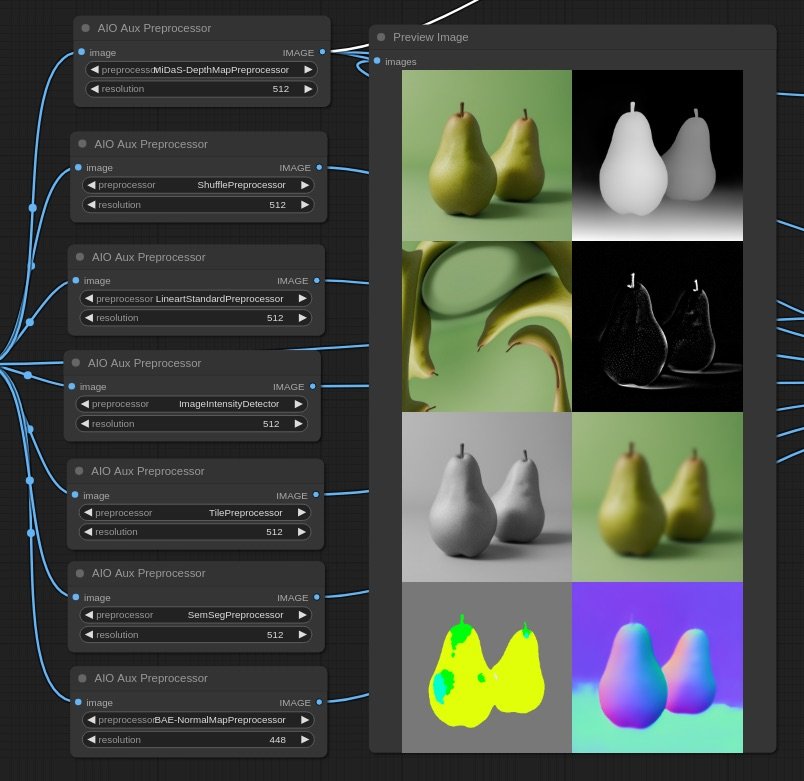
Polar Bubbles breaks down daily news with a flavour: every story comes with two opposing takes—one far-left, one far-right. Each take has two versions: a clickbait headline and a straightforward, informative one. That’s four headlines for the same story, showing just how wild framing can get.
It’s all about exposing the madness of polarization, media manipulation, and those sneaky algorithms that decide what you see. By laying it all out, Polar Bubbles shows how news shapes what we think, feeds our biases, and drives us further apart. It’s a reality check for anyone stuck in an echo chamber.



toolset:
News are fetched via newsapi.org,
Titles made with a LLM (GPT-4o-mini)
System instructed as following:
self.prompts_politic_left = """ Adopt an extreme far-left, progressive perspective with a heavy socialist viewpoint. If the news seems positive from a capitalist or conservative standpoint, frame it as negative or problematic. If it seems negative from that standpoint, frame it as a positive step towards socialist ideals. Emphasize one of the following randomly: wealth redistribution, workers' rights, environmental activism, or social justice.""" self.prompts_politic_right = """ Take on an extreme far-right, ultra-conservative stance with a heavy nationalist perspective. If the news seems positive from a socialist or progressive standpoint, frame it as negative or threatening. If it seems negative from that standpoint, frame it as a positive development for traditional values or the free market. Focus on one of these aspects randomly: traditional values, free-market capitalism, national security, or anti-globalization.""" self.prompts_tone_viral = """ Create sensationalist, emotionally-charged clickbait. Use shocking language, exaggeration, and inflammatory rhetoric to gain views. Keep it very short and viral. Add emoji if it enhances the tone. Randomly incorporate one of these elements: unexpected statistics, conspiracy theories, or urgent calls to action.""" self.prompts_tone_formal = """ Craft an informative, journalistic headline with complex vocabulary and detailed analysis. Describe why the news is significant, good, or bad, ensuring this aligns with the given political bias. Emphasize positioning and context. Randomly focus on one of these angles: historical parallels, economic implications, societal impact, or future predictions."""
Glossary

VR TERROIR
Exploring user’s representations in virtual environments with contextual, non-generic avatars rooted in culture and space.
Goal: Bring the richness and entropy found in natural materials to the digital space to create diverse digital identities.
Why: Character design in XR applications lack the richness found in other media. This can be due to the historical technical restrictions of the mediums or the heavy platformization of the space.
What am I fighting?
Corporate positivism and standardisation, reduction of self expression to controlled archetypes and homogenisation of visual culture.
As in other areas of the digital existence, services and spaces offered (controlled) by profit-prioritising entities (companies) tend to operate from a risk-averse neutrality, where companies enforce strict, controversy-free environments to avoid any potential backlash. This approach propels culture towards a Hyper-sanitized mediocrity, a reality where only the safest, most generic content survives.
This is happening offline and online, we see it in content moderation of user generated content, specially text, images and video, where Algorithmic puritanism reigns with overzealous, automated censorship (nipple) that enforces arbitrary moral standards.
To reclaim spaces free from dictating aesthetic standards we need tools to build them.
Why this matters, and why in XR/VR?
Access to the means of creation is common, ubiquitous and affordable, media creation is within reach to the broader public, who flood instagram with photos, tik-tok with videos and their work wit template-driven designs. This is great, but also heavily controlled.
While which photos a camera can take can't be controlled (yet, although you can’t scan money), what is heavily limited is where the media can be shared.
As platforms are hungry for content, new and novel tools are given to people to create stuff, specially for platform-specific behaviour-based media such as cam-filters, reacting memojis, or avatars.
In this cases, we see the above-mentioned limitations of censorship happening before the creation, in the form of limitation.
These walled gardens are often camouflaged as "paradox of choice", where the user is provided with seemingly a lot of freedom as long as it happens within the predefined boundaries.
3D creation, whilst being popularised with tools such as wamp or easy image-to-3D services, has a steep learning curve, with complex softwares and functionality pipelines that makes the creation of unique avatars a craft. So, users still rely on platform-provided tools to define their digital existence, or user-generated content which is also heavily monitored.
VR_Terroir is one of many directions identity and aesthetics in avatars can take to questions the aesthetic narratives of digital presence, going away from the corprorate-positivism of superficial-profyling avatars, with a texture-rich non-anthropomorphic approach, and is based in the artist's appreciation of the richness found in nature, the expressivity in folk culture, attitude in fashion and detail in character-design.
What: A system to create 3D digital characters based on images and contextual information.
Technically: Input a photo of a texture, get a 3D avatar.
Possible production directions:
Tool: A web-app to generate 3D avatars
Artifact: A camera with a hologram display: (tangible version of the web-app)
Artwork: Real photos of places in Europe, with their characters. Similar to bigfoot viewing, or fairies in forests, gods in mountains...
[WIP Dec’24-Jan’26] : A project from the S+T+ARTS EC[H]O residency
challenge: Virtual Representations of Users / Spatial Computing
context: Virtual Reality, Scientific Visualisations, Collaboration, Avatar, Design
keywords: Biases & Challenges / scientific datasets / creative potential / realism and abstraction / nonverbal communication / perceptions.
VR TERROIR explores the virtual representations of users. in collaboration with the High Performance Computing Center in Stuttgart (HLRS), who have a solution to explore scientific data in Virtual or Augmented Reality settings, allowing for remote and multiple users to be present.
It is an amazing tool, but there is a missing piece of the puzzle: how do we represent users there, in a non uncanny valley way, supporting non-verbal communication and with a right degree of realism and abstraction?
My proposal, in a nutshell is: building from the existing rich and cultural background of hyperlocal particularities found in popular culture, heritage, nature and space, physical and digital

We could call it the Avatar Terroir. same as in wine, where the terroir defines the complete natural environment in which a particular wine is produced, including factors such as the soil, topography, and climate.
Going from: a fake, generic, loud, bias, profiling, sterile and simplistic representations of self.
To: Using treats of the local culture, materials and place.
On the left, we place the current state of avatars, which are mainly an expression of Corporate Optimism, hyper functional, median, politically correct digital beings. From the cuteness of apple’s memojis, to Meta’s cartoon clones.
There are also places of extreme niche self expression, as virtual communities like VRCHAT, where a plethora creatures roam around polygons. Those avatars are wild and creative and fantastical, but are mainly rooted in digital culture, lacking a sense of place or context.
And here on the right, where I want to go, is the existing representations of beings and humans by popular culture. We do have a rich, tactile, physical heritage of creatures in europe.
From these down there from the basque country in northern spain, who dress with sheep wool and giant bells, to this guy from hungary. I do not aim to make a direct translation of all of this, but this is to illustrate the physicality I aim to achieve, also taking from identifiers of the localities, from the Kelp of Greece or the moss in some Alpine forests.
I also want to explore how the digital context within a digital environment can drive the representation: since it is a scientific visualisation environment, how avatars should look behave or be affected if we are exploring nano microbial data or outer space simulations?
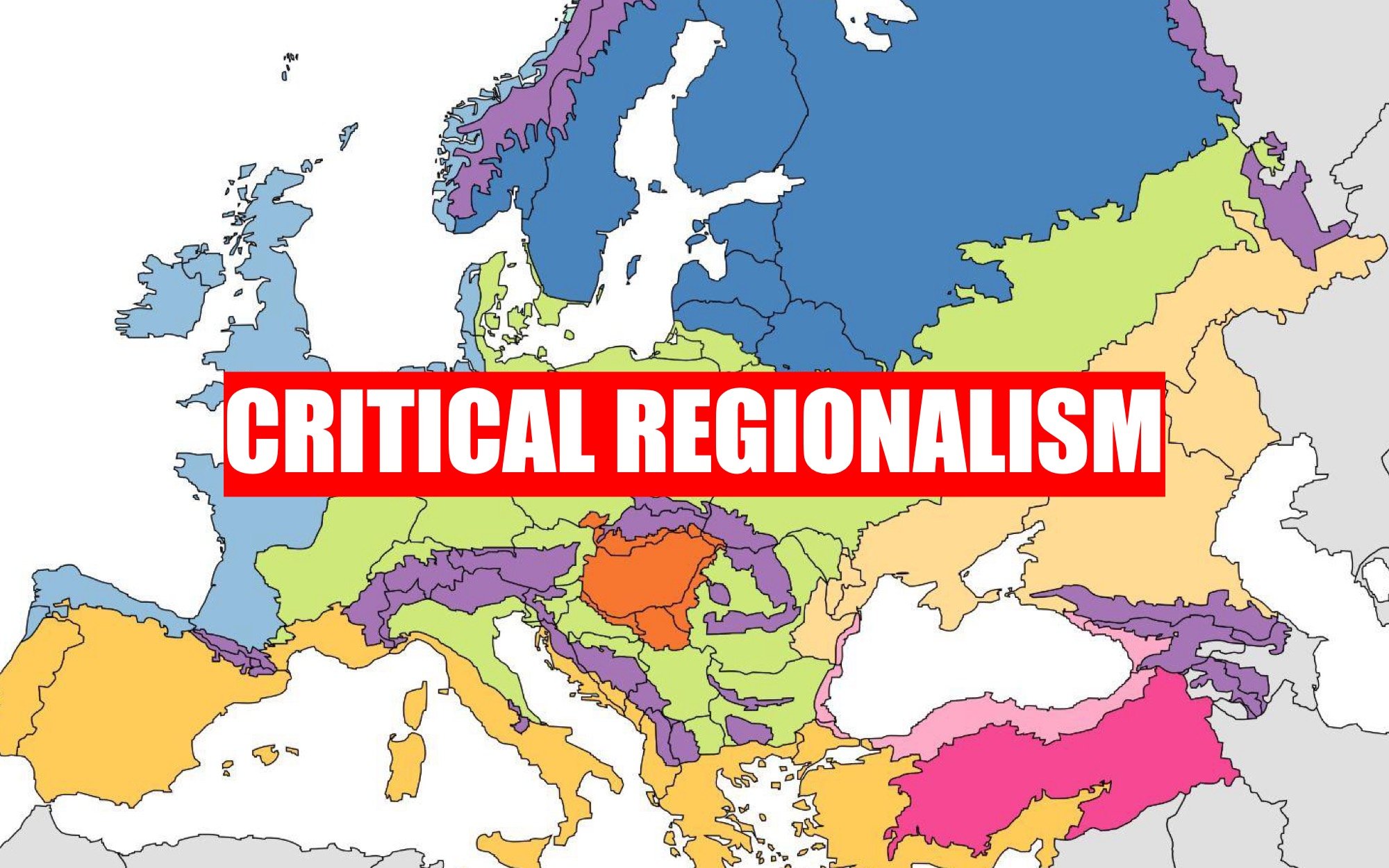
It turns out that this have a name :)
I’ll tap into the Critical Regionalism movement in Architecture, that reject placelessness of postmodernism and reclaims a contextualized practice, using local materials, knowledge, culture while using modern construction technologies.
For insance, the image in the background is a map of the Bioregions in europe, geographical areas with a similar biodiversity and common geographies. This could be a starting point, to break away from country boundaries that tend to be simplistic and profiling. For exampleinstance, I feel more mediterranean than spanish; in some aspects I have less in common with someone in the woods of Galicia, and more in common with someone from the coast of Lebanon.
Could the type of trees, the style of the cities or the food grown and eaten on a certain place drive the look and feel of avatars?
If this sounds political, is because it is,
digital spaces are colonized with globalized corporative capitalist extractive practices, Google Facebook Amazon and Apple dominate the language, the platforms and the narratives.
And I believe we need to build tools to reclaim identity and agency.

And how to do all this?
With my skillset, Digital Craftsmanship, coming from an industrial design background, I’m familiar with the world of making things, and over the years I’ve been intentionally de-materializing my practice and designing for the digital space, because I don’t see a reason strong enough to add make more stuff to the world. So I have experience in 3D environments and digitization.
For this project I envision using 3D scanning, computer vision, generative textures, parametric design, computational photography, generative AI, motion capture.
As a hint, what I could see myself doing in this project is climbing a mountain deep in the carpats, 3D scanning a rock and feed it to a generative system that blends it with a scientific dataset and proposes avatars.

VR TERROIR : contextual placefullness
FRAMEWORK

Technical scope

Research

references / inspiration / links
links database → https://cunicode.notion.site/129454e7e114817e9ac2e1fc298a9241?v=129454e7e1148128ae00000cd13f0c98
Technical context
From the Host: HLRS
VR tools and facilities
Software developed at HLRS transforms data into dynamic projections. Wearing 3D glasses or head-mounted displays, users of our facilities and other tools can meet in groups to discuss and analyze results collaboratively.






Wearing 3D glasses, users can step inside simulations in this 3x3 meter room. Using a wand, it is possible to move through the virtual space and magnify small details.
Collaboration in virtual reality
When face-to-face meetings in the CAVE are not possible, software developed at HLRS enables persons in different physical locations to meet and discuss simulations in virtual reality from their workplaces or home offices.
Software
The Visualization Department at HLRS offers powerful virtual reality and augmented reality tools for transforming abstract data sets into immersive digital environments that bring data to life. These interactive visualizations support scientists and engineers across many disciplines, as well as professionals in nonscientific fields including architecture, city planning, media, and the arts.
COVISE (Collaborative Visualization and Simulation Environment) is an extendable distributed software environment to integrate simulations, postprocessing, and visualization functionalities in a seamless manner. From the beginning, COVISE was designed for collaborative work, allowing engineers and scientists to spread across a network infrastructure.
VISTLE (Visualization Testing Laboratory for Exascale Computing) is an extensible software environment that integrates simulations on supercomputers, post-processing, and parallel interactive visualization.
Other tools and technical solutions for this project:

Visual Language Models: for understanding images
Generative 3D models: for giving shape to concepts
Parametric Design: For computationally define boundaries and shapes
Gaussian splatting: For details and visuals beyond meshes and rendering
Computer vision: for movements and pose estimation
Depth estimation / video-to-pose
3D scanning: for real world sampling
photogrammetry / dome systems / lidar / optical scans
Image generators: for texture synthesis
Societal context
Understanding the role of avatars in culture
Bibliographic research at the library collection from the Museu Etnològic i de Cultures del Món looking for folklore representations of beings.
[non-human / human] representations in folk culture
Pagan / material-rich costumes / masks.
A good repository of material qualities of costumes is found on the work Wilder Mann by Charles Fréger:

photos: Wilder Mann by Charles Fréger
Other sources consulted include:
The photographies by Ivo Danchev, specially the Goat Dance collection
Masques du monde - L'univers du masque dans les collections du musée international du Carnaval et du Masque de Binche
Mostruari Fantastic (barcelona)
El rostro y sus mascaras (mario satz)
Analogies and parallels
Expressive avatars at edge digital cultures (Vrchat)
VR spaces
Costuming Cosplay Dressing The Imagination (Therèsa M. Winge)
Webcam backgrounds as a shy attempt to self expression















Relationship between the human body, space, and geometry [ Bauhaus ]
DEV / WIP / EXPERIMENTS / PROOF OF CONCEPT
Proof of concept 01
Characters informed by the materiality of their context.
In this experiment, I combine the aesthetics, material and texture characteristics of a setting [microscopic imagery, fluid dynamics, space simulations…] and translate them to visual cues shaping and texturing a character.












Visit at the HLRS and Media Solutions Center - January ‘25
Demo of equipment, projects, use cases and vision
With the aim of including humanistic thought and sociological context in this project, a conversation was arranged with the Head, Department of Philosophy of Computational Sciences at HLRS: Nico Formánek
Some of the concepts discussed were:
How do we “represent”?
Representation is a choice
When something is defined/described (i.e in thermodynamics) there is a whole set of things that are undefined.
Every choice leaves something out. (as per Jean-Paul Sartre’s concept of "choice and loss" —that every decision involves a trade-off, meaning something is always left behind. Sartre’s idea of "radical freedom" suggests that we are condemned to choose, and in choosing, we necessarily exclude other possibilities.)
Oportunity for this project to make explicit what is left in its choices
The concept of positioning: in a social context
How conventions apply in digital spaces / VR?
Standing - relationships between two things
How context guides standing. (i.e music in opera)
References: Claus Beisbart
Virtual Realism: Really Realism or only Virtually so?
This paper critically examines David Chalmers's "virtual realism," arguing that his claim that virtual objects in computer simulations are real entities leads to an unreasonable proliferation of objects. The author uses a comparison between virtual reality environments and scientific computer simulations to illustrate this point, suggesting that if Chalmers's view is sound, it should apply equally to simulated galaxies and other entities, a conclusion deemed implausible. An alternative perspective is proposed, framing simulated objects as parts of fictional models, with the computer providing model descriptions rather than creating real entities. The paper further analyzes Chalmers's arguments regarding virtual objects, properties, and epistemological access, ultimately concluding that Chalmers's virtual realism is not a robust form of realism.
new book: Was heißt hier noch real? (What's real today?)
Proof of concept #3
Using gaussian splatting to represent detailed material features
-> scan of the Triadisches Ballett at the Staatsgalerie Stuttgart
Text 2 3D models

challenge:
need to find: if a system can output a turntable of the creation before the meshing step, it could be possible to nerf it, and create a neural representation of the volume, without going through triangles…
HLRS collab
Meetings with the HLRS team to discuss the project. Some of the things we discussed are:
VR continuum and role of the CAVE systems
XR expos and industry events
Remote Access to a GPU cluster
Access to photo-scanned materials and textures
Use-cases for avatars in HLRS
Tech Sessions
Meetings with Carlos Carbonell to explore the technological soundess of the idea and preceding , existing and future solutions.
Session: History of identity in digital spaces and vr platforms
Session: Hardware setup.
Session: visit at Event-Lab at the Psychology department from the Universitat de Barcelona - where they carry out technical research on virtual environments, with applications to research questions in cognitive neuroscience and psychology. We were hosted by Esen K. Tütüncü who showed us their research projects, equipment, pipelines and vision.
Session: we’ve did a VRCHAT tour, exploring different spaces, avatars and functions.
Trying on avatars seems the most fun (for me)
It seems to be a popular thing to do there, as there are many worlds for avatar hopping.
Some avatars are designed with great detail, with personalization features, physics, particles and add-ons
It is interesting the self-exploratory phase of looking at oneself every time you get a new avatar
Portals are a fun to land to unexpected places
There is a feeling of intentional weirdness, where avatars, spaces and functionalities are strange for the sake of strangeness.
Photogrammetry in VR: some speces are built or contain 3D scans. Due to technical limitations, those scans look bad.
Some programatically built objects have rich features, such as collisions and translucency.
Scale is a powerful factor in VR. Being tiny or giant really changes the experience












Next Sessions
Meetings with Dr. Claudia Schnugg to discuss and explore how to shape this project for continuation beyond the residency
Glossary

Adversarial Violence
embed social critique within images, to force algorithms to verbalise and expose inequalities.
Machine vision & silenced stories



The aim is to force the algorithm to tell me what is there but is not seen.
The conceptual framework of this attack, is to embed social critique within images to force algorithms to verbalise and expose inequalities.

Captioning is the process to identify objects, scenes and relationships in an image and describe them. This has traditionally been used to make media more accessible and contextualized.
In early days of web 2.0 flickr pioneered tagging and captioning image descriptions, where users enhanced their photos with a descriptive narrative of what was being displayed.
Later on, AI companies fagocited all that content (and more) to build their automated machines.
So now, using API’s and services, it is possible to automagically compose a description of an image.
But what description? From which point of view? Who is telling the story?
It is often the mainstream perception, the forced averageness.
A transactional visual interpretation that avoids the violence of current times, the exclusion, the abuse and the inequalities of the economic system.
Adversarial attacks are a technique to modify a source content in a manner to control what machine learning models see on them, while being imperceptible to human eyes. This raised alarms around 2017 when it was presented in research environments, as it exposed the fragility of the algorithms that many corporations praise and depend on.
I feel that AI is a beautification of capitalism’s negative impact, a makeup of niceness and solutionist efficiency. With AI’s expansion and gooey omnipresence, it becomes hard to see the edges, the labor, the pain and the suffering that tech companies and shortermist policies ignore and exhacerbate.
Here I’m imperceptibly perturbing an image (A:Nice housing) to display the content of another image (B:homelessness and city’s precariety) to a captioning model (im2text).

Captions for original image original_housing_256.png.npy:
1) a large building with a clock on it (p=0.000326)
1) a large building with a clock on it . (p=0.000312)
1) a tall building with a clock on it (p=0.000229)
*I expected a nicer description as “white house, clean design, sunny weather”, but I got a very disappointing scarce string of words

Captions for target image homeless_2_256.jpg:
1) a man sitting on a bench in front of a store . (p=0.000008)
1) a man sitting on a bench in front of a building . (p=0.000004)
1) a man sitting on a bench in a city street . (p=0.000004)
*Here I’m also expectedly disappointed as the model nice-washes the scene
🥸 success:
The image now carries the injected visual qualities to fool the model to view the second image, thus creating captions of what only the machine (that specific algorithm) sees, but not the human eye.
Captions for adversarial image adversarial_housing.png:
1) a man sitting on a bench in front of a store . (p=0.000261)
1) a man sitting on a bench in front of a building . (p=0.000120)
1) a man sitting on a bench in front of a store (p=0.000052)🤦♂️ failure:
The model used here is not even able to describe a homeless / precariousness situation, thus we can’t embed that description to the source image.
🛠️ tools:
IBM/CaptioningAttack - Attacking Visual Language Grounding with Adversarial Examples: A Case Study on Neural Image Captioning
🤖 outdated approach:
currently with the use of Large Multi Modal models this approach renders anecdotical, as the language models have the capacity to scramble text coherently enough to build a use-case for a specific situation.



I still like the beauty of potential unexpected critique of targeted adversarial attacks
📷 image credits
housing 01: Photo by Krzysztof Hepner on Unsplash
housing 02: Photo by Frames For Your Heart on Unsplash
food: Photo by Marisol Benitez on Unsplash
farm worker: Photo by Tim Mossholder on Unsplash
fashion: Photo by Mukuko Studio on Unsplash
trash: Photo by Ryan Brooklyn on Unsplash


WTFood
🥬 curiosity -> action 🤘
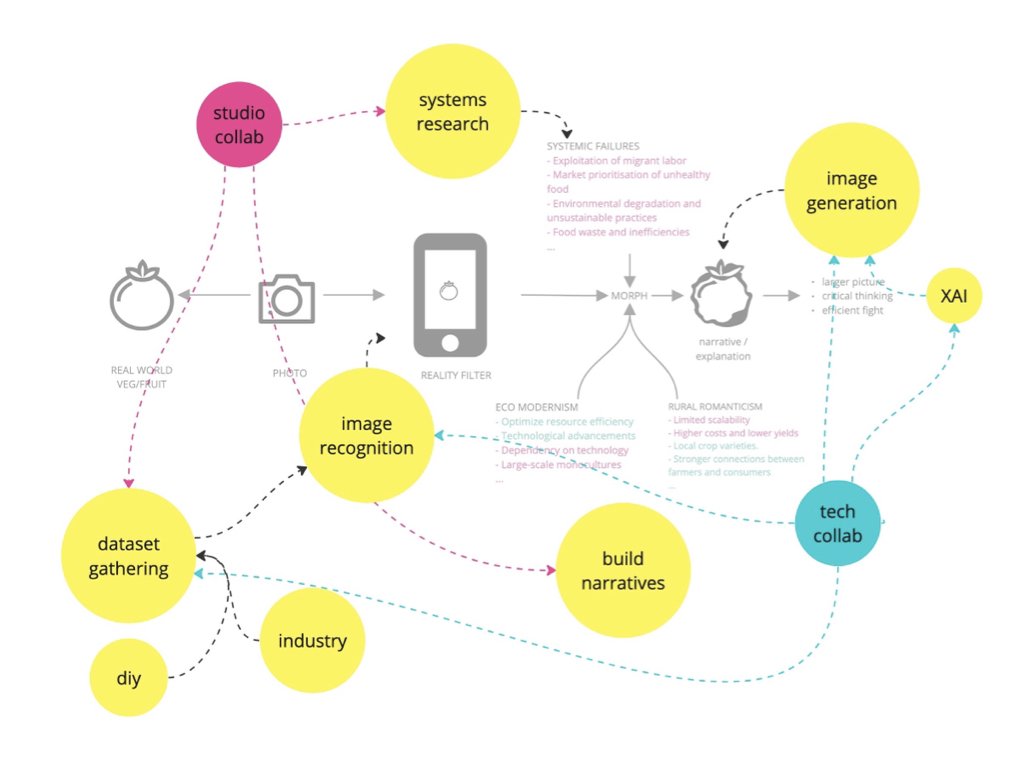
Exploring the systemic socioeconomic glitches of the food system through the lens of multiple agents.
A lens to explore systemic socioeconomic glitches in the food system and discover ways to take action. From curiosity to activism.
🥬 curiosity -> action 🤘
*
🥬 curiosity -> action 🤘 *
You feel that something is wrong with the food system, but you still don't know what to do about it.
Take a fruit or vegetable, open the camera, and watch it morph into a glitch of the food system.
The glitch, is the socioeconomic impact of certain practices, policies or market forces.
You already knew that, you feel it when you go to the supermarket and everything is shiny and beautiful, and all the packagings and advertisings show you happy farmers.
Where are the precarious workers?
Where are the small stores that can't compete with large distribution chains?
Where are the industrial growers whose produce feeds cheap processed salads that will mostly end as waste?
WTFood will show you this, and will also show you links to people, companies, communities and policies that are fixing this glitches near you, so you can take action.
Use it again, and a new systemic glitch will appear.
Each time from the point of view of different people involved in the food system.
The Map
You are not alone, each tile of the map is a story triggered by someone else. Together, we collaboratively uncover a landscape of systemic glitches and solutions.
Desktop:
click-drag to pan around the map, and use your mouse-wheel to zoom in-out.
when you click to a tile, it will center-zoom to it.
click anywhere on the grayed-out area to navigate again
Mobile:
swipe up/down/left/right to jump to other tiles
pinch with two fingers to zoom in-out and pan

The Sorting
You can explore this map by seemingly unrelated categories.
enter a word or sentence in each box
hit SORT to see how the cards arrange accordingly
navigate the map as usual

Status
This is a "digital prototype", which means it is a tool built as a proof-of-concept; and as such, it has been built with some constrains:
Content
The issues of the food system have been narrowed down into the following 5 areas:
Power consolidation
Workers' rights and conditions
Food distribution and accessibility
Economic reliance and dependence
Local and cultural food variations
The perspectives have been limited to 5 stakeholders, subjectively chosen by their impact and role in the food system:
Permaculture local grower
CEA industrial grower
Supermarket chain manager
Wealthy consumer
Minimum wage citizen
Functionality
🧑💻 The system works beautifully on a computer, specially the Map and Sort
📱 Android is preferred for mobile use
⚠️ Avoid iPhones as videos do not auto-play and map navigation is sluggish and confusing.
⌛️ Video creation and link making takes about 50 seconds.
👯 Multiple users might collide if a photo is sent while a video is created, so your image might be lost or appear on another tile.
🍑🍆 Non-fruit-or-vegetables photos won’t be processed
The system has two modes: Live / Archive
Live: you can use it to add photos and generate new videos and links and browse and sort existing tiles. Live mode will be enabled until the end of May 2024, and probably during some specific events only.
Archive: You can use it to browse and sort existing tiles. This will be the default status from June to December 2024
Data & Privacy
Photos you upload are used to create the video and run the service. They're stored on our servers.
Location: We use your IP address (like most websites) to show you relevant local links, but we don't sell or trade any data.
🙌 Open source code: The code is available for anyone to use and see. → github
The Digital Prototype
The technical development has been performed focusing on adaptability and easy deployment.
The software package has scripts to install all the components and required libraries.
The code has been made available as an opensource repository at GitHub
The main components of WTFood are:
Photo capturing and contextual labelling: an easy to use interface to securely and frictionlessly open the device’s camera (mobile) or allow for a photo upload (desktop):
Crop the image to 1:1 aspect ratio
Identify if it contains any fruit or vegetable
Detect the most prominent fruit or vegetable and label the image accordingly
Based on user’s IP, identify generic location (country + city)
Story building and link crafting: A chained language model query based on 4 variables: issue + stakeholder + identified-food + location. This model is built with LangChain, using Tavily search API and GPT as the LLM. (this code was built prior to to GPT’s ability to search the web while responding).
Explain an issue from the perspective of a stakeholder and related to the identified food
Build an engaging title
Describe a scene that visually represents the issue explained.
Search the web and find 3 relevant links to local events, associations, policies or media that respond to “what can I do about it”, and rephrase the links as descriptive titles according to their content
Visualizer: A generative image+text-to-image workflow developed for ComfyUI that does the following:
Given an image of a fruit or vegetable generates additivelly 4 images that match a textual description.
The images are interpolated using FILM
A final reverse looping video is composed
Cards: An interactive content display system to visualize videos, texts and links
Mapping: Grid-based community generated content: a front-end interface that adapts and grows with user’s contribution
Sorting: A dynamic frontend for plotting media in a two axis space according to their similarities to two given queries. This component uses CLIP embeddings in the backend.
Since the code is built with modularity, each of the avobe mentioned componens can be used independently and refactured to take the inputs from different sources (i.e. an existing database, or web-content) and funnel the outputs to different interfaces, (i.e: a web-based archive, or a messaging system…).
This flexibility is intentionally designed for future users to implement the desired component of the WTFood system to their needs.
Next Steps
This prototype will be used on the 2nd phase of the Hungry EcoCities Project.
Wtfood can be useful for many kinds of SME's and associations as the system is robust and built for flexibility and customization. Here are some potential use cases:
Engaged Communities: As the image classifier can be fine-tuned to accept photos within very specific categories, associations can leverage the platform to launch challenges around (weird) specific themes such as "food in the park" or "salads with tomatoes"
Interactive Product Exploration: Companies can create dynamic explorable product maps categorized by user-defined criteria.
Event Dissemination: Communities can adapt the system to promote and share links to upcoming events and activities
Credits
Artist: Bernat Cuní
Developer: Ruben Gres
WTFood is part of The Hungry EcoCities project within the S+T+ARTS programme, and has received funding from the European Union’s Horizon Europe research and innovation programme under grant agreement 101069990.
✉️ contact: hello@wtfood.eu
Work, concept & code under HL3 Licence

👇 Below, a journal of the project development, with videos, research links and decisions made
09-2023 / 05-2024Food Dysmorphia uses AI technology to empower citizens to critically examine the impact of the industrial food complex through aesthetics and storytelling. It addresses the hidden economic aspects of the food system, revealing the true costs obscured within the complexities of the food industrial complex. The project maps out food inequalities, visually representing externalized costs to enhance understanding. It aims to develop a "reality filter" using AI and computer vision, altering images of fruits and vegetables to reflect their true costs, thus facilitating discussions, actions, and knowledge sharing. The target audience includes individuals interested in sustainability, food systems, and social change, especially those open to deeper exploration of these topics. This is a political project, shedding light on the political dimensions of the food industry and its societal impact.
A Hungry EcoCities project
team: Bernat Cuní + EatThis + KU Leuven Institutes + Brno University of Technology + In4Art
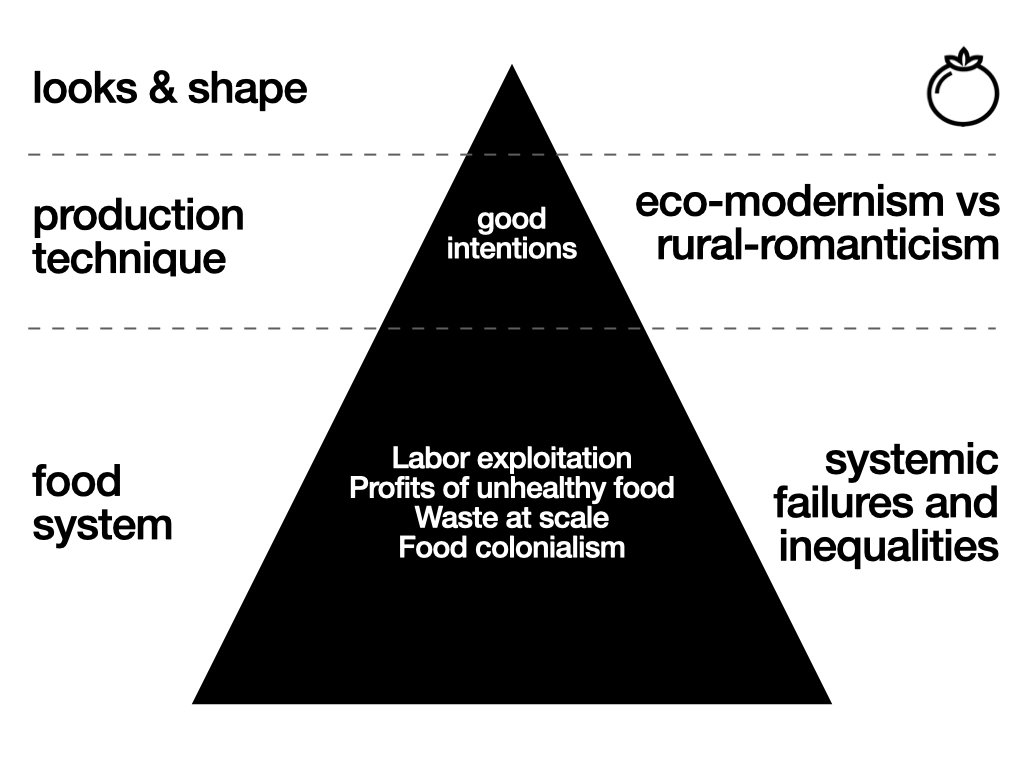
Exploring systemic failures and opportunities through the food’s look & feel
Utilizing generative AI and computer vision technologies, this project will use reality filters to narrate food realities and uncover untold stories, shedding light on system failures and food-related issues
research & references links -> food.cunicode.com/links
initial approach


































this project answers the specific research direction:
The eco-modernism / alternative food production systems standoff
In the 2022 documentary The Future of Food eco-modernist Hidde Boersma and advocate for more traditional nature inclusive inspired food production practices Joris Lohman challenges the dichotomies that are between them. Boersma and Lohman represent a large societal standoff between those who believe in tech driven innovation in agriculture (Boersma) and those who reject the influence of modern technology and advocate living in closer harmony with nature by i.e., adhering to the principles of i.e. permaculture (Lohman). The documentary shows how this (Western) standoff is preventing the change in the food system, and that there are things to gain if we listen more to each other. Both ‘camps’ claim they are the true admirers of Nature: the eco-modernist by trying to perfect nature, the perm culturalists by complete submission to nature. It begs the question whether both viewpoints are at odds with each other or if an ecomodernist permaculture or a permacultural eco-modernist garden would be feasible? Could we explore if a hybrid model could have benefits? What would a food forest inside a greenhouse look like? What additional streams/ functionalities can be supported by the greenhouse? Can greenhouses become more nature/ biodiversity enhancing spaces? How could recent biome research in biosciences be introduced into CEA systems? What type of data models would be necessary to support it? But also the opposite direction could be explored: What would adding more control to alternative practices like biological or regenerative farming yield? How would the AI models used in CEA respond to a poly-organized production area?
DEVELOPMENT
below, all the content that I develop for this project, probably in chronological order, but maybe not.
Food? which food?
Contextualising “food” for thid project: include fruits and vegetables, excluding growing and distribution stages, and post-consumer or alternative processing stages
Why How What
Positioning the project
The starting point
“capitalism shapes the food system, and while most of the actors act in good faith, collectively the food system is filled with inequalities, absurdities and abuses, and because the food system is not organised as a system but more of a network of independent actors, those systemic failures are apparently nobodies fault. I believe that what ties it all together is capitalism, which being extractive by nature it rejects any non as-profitable-as-now approach. Thus a fight for a fair food system is an anticapitalist fight.” initial biased assumption
Narratives (possible)
-
Do all technical innovations benefit the profits, not the consumer?
-
is not that we do not know how to make food for all the world, it is that we do not know how to do it while accumulating large amount of profits
-
Preventing something “bad” is more impactful than doing something “good”
-
Item description
-
If food is not affordable or accessible, it perpetuates inequalities
Field Research / technofetishism
Together with other HungryEcoCities members, we did a field trip to Rotterdam to visit the Westlands, the place where horticulture is booming.
At the Westland Museum, we learned about the history (and economics) of greenhouses and how crucial was for Holland to have a rich industrial England to sell expensive grapes to. We visited Koppert Cress and saw how robots (and people) grow weird plants that fit their business model of catering high-end restaurants. We explored the +45 varieties of tomatoes at TomotoWorld and saw how they use bumblebees to pollinate their plants. At the World Horti Center we were presented the techno-marvels that are supposed to keep the Netherlands on top of the food chain. I also went to Amsterdam to meet with Joeri Jansen and discuss behaviour-change & activism from an advertising point of view. There, while at the hipster neighborhood of De Pijp 🙄 I visited De Aanzet a supermarket that presents two prices to the customers, the real one, and the one including the hidden costs, so the customer can decide to pay the fair price or not.
Project KPI’s flow

Visual Classifier / fruits and vegs
Testing different approaches to build an entry touchpoint to FoodDysmorphia.
goal: process images of food (fruits & vegetables) and reject non-food images/scenarios/content
A classifier is needed: local running python = √
Remote: via huggingface or virtual server / or using an API as Google’s AI-Visoin


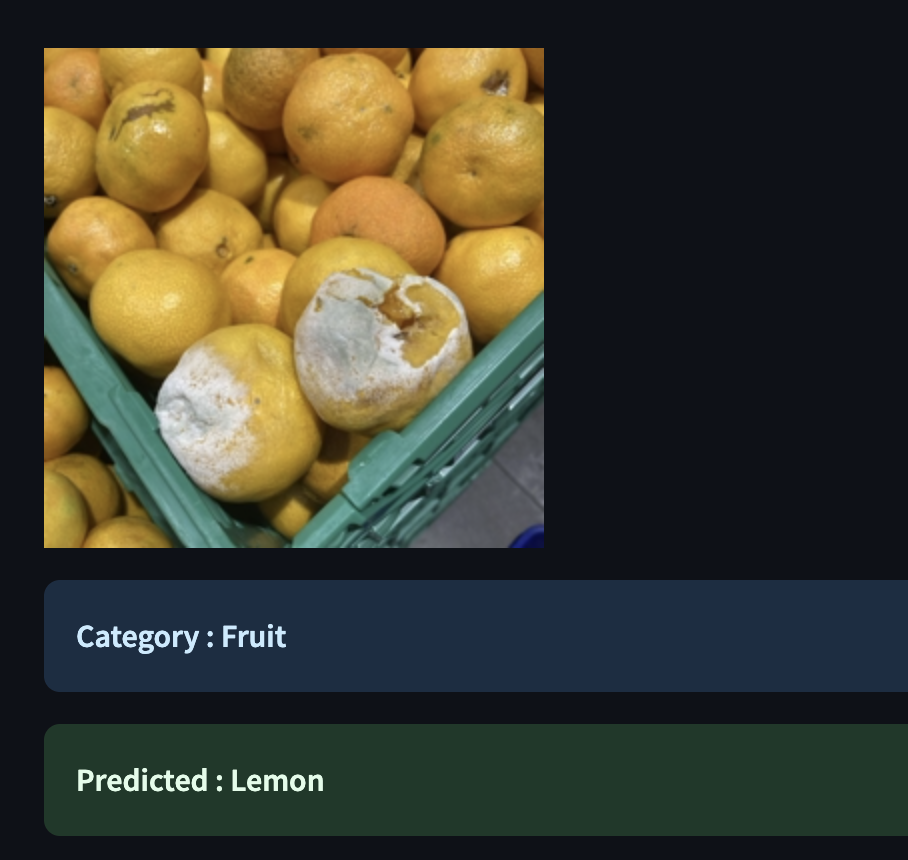




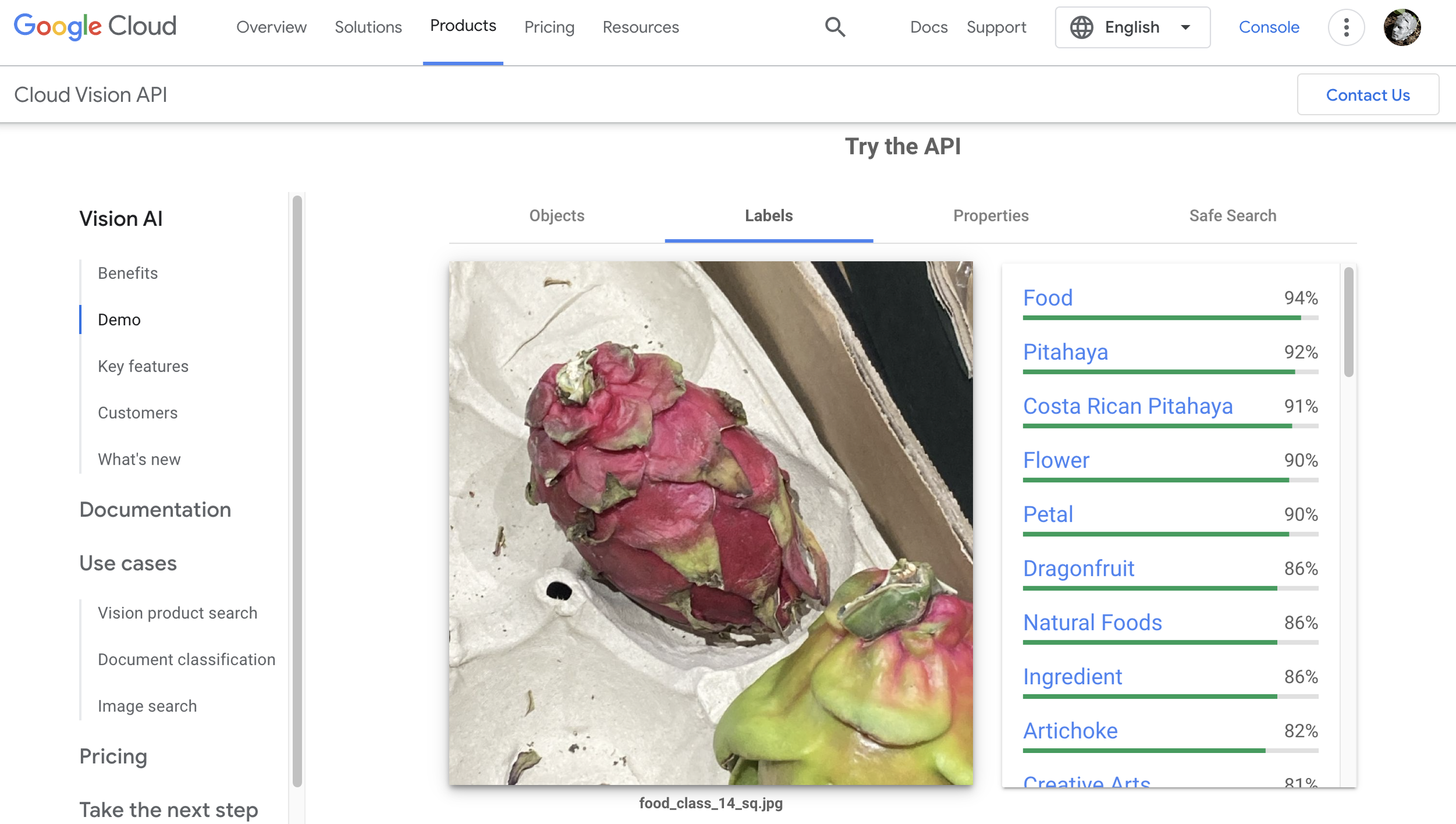


field research
finetune
learning: when bringing the cost issue into the table, the conversation is not the same anymore (good)
Frame the anticapitalist narrative within the ecosystem, together with solutions, approaches, facts, easthetics -> to not be perceived solely as a naive rant.
conceptual framework

Technical Aesthetics Exploration
Mapping the narratives of the food system
Focus Exercise

“write a press release as if the project is already done”
This helped to frame/visualize/experience the ongoing project concept into something tangible.
Month 1 + 2 / development report
Challenges
At this point, the critical things to decide are.
Find the Aesthetics:
GenerativeAI is a copy-machine, it fails at “realistic photorealist” (meaning, that is capable of making perfectly beautiful hands but with 7 fingers 🤦♂️), and is able to replicate existing visual styles.

Trying to avoid photorealism, a graphics-oriented aesthetics could work.
Propaganda poster aesthetics is explored as a starting point.
flat colors / defined shapes / complementary chromatic schemes






Find the Voice
who is telling the story? the food? the people in the food system?
finding the characters/agents/individuals to tell stories through
stereotypical profiles of food system’s agents
Call to Action
What do we want to happen? Find a balance between activism / alarmism / solutions
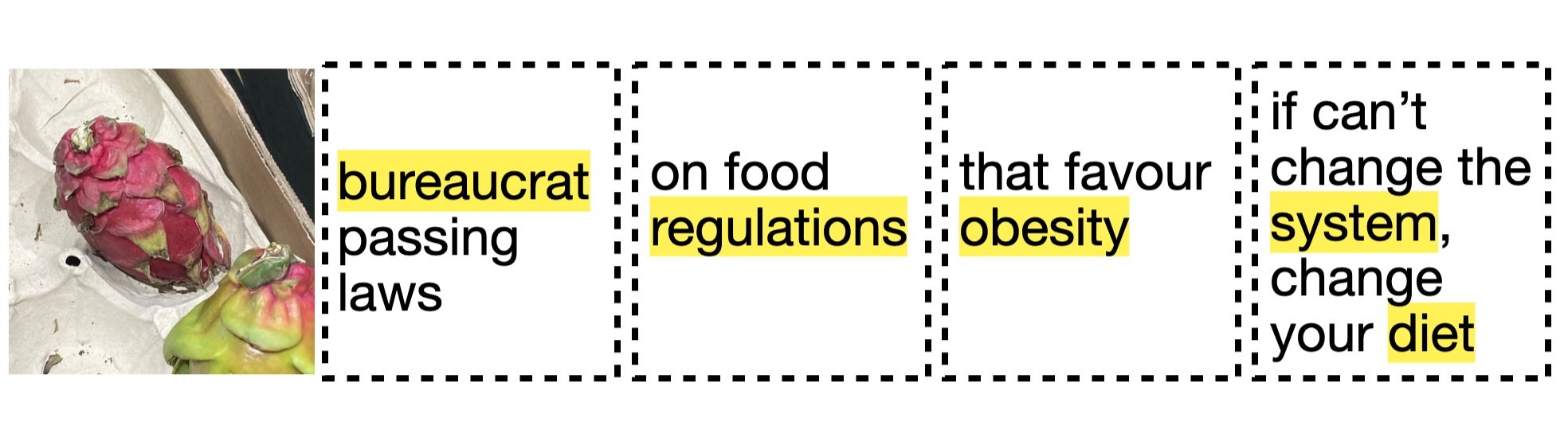
exploring the possible multi-step process to tell a story: upon image submitted, an agent (person) starts the narrative / sets the context / problem exposed / action-solution
Technical context checkup:
Why AI?
at scale / reach / framework where things can happen
averageness / common denominator / popular culture
Why AR?
relatable / personal context
point of reference
Group Session / Turin Nov’23
2 full time days with presentations & discussions. led by Carlo Ratti Associati team.
I structured my presentation with an intro to my relationship wiht AI tools and how they tend to the mainstreamification of content, and how this relates to the project.
For this project the use of AI is actually related to the averageness, to use a tool capable to communicate/condense concepts in the most transversal and understandable way for many types of audiences.










For each presentation each of the members took notes and added comments to a feedback form that was then shared.












Next steps
From the discussions and feedback the areas of further research are the following
this sounds like a tactical media project. (context)
potential polarising effects (desired?)
how to avoid eyerolling 🙄
limit the scope/effect of the output? geographically / sector / company ?
Thoughts
The problem with pointing things out: nobody cares.





I’m subscribed to multiple newsletters and communities around food, and I find myself deleting emails before reading them, same with climate change content, same with other issues… It is not about the information… it is not about the data.
Why Why Why?
When researching a topic, often all roads point to capitalism systemic economic failures. Food is no exception.
so, maybe instead following the thread (positive or negative) we can showcase that path, and communicate a narrative without overwhelming with data or pointing fingers and losing the audience half way… 🤔
Here is this bit by Louic CK, where he explains how kids keep asking “why?” endlessly. is fun, and it is also an Iterative Interrogative Technique, that made me want to try it out.
I instructed a language model to behave in such way, the “5Why” model, with a goal to link any given insight to economic reasoning.
And it works! and the best is that it works for positive and negatives scenarios as:
“why fruits are so beautiful at the supermarket?” gives a reasoning towards market preferences and how this influences the farmers
“why buying local is good?” explaining how this strentens comunities and makes them more resilient within the global economic context



The multi-dimensional map of inequalities
During the by-weekly discussions with the project partners, the question of why/when would someone use this often arises. And linking it with an early conversation with a behavioural media campaign publicist I met in Amsterdam in October, I explored the concept of “giving something to do to the user, a task”
The idea here is that each individual’s actions contributes to a greater result. As analogy, we can use an advent calendar , where each day you unlock something that gets you closer to the goal.
Also, since the project is about showing multiple narratives/realities of the food system that are behind every product, we must find a way to show that variability.
Also, some partners rise concerns that the project is too biased towards demonising corporate practices (which it somehow is), thus a way to tell their story needs to be contemplated.
Mixing all this up, we can now frame the project as a collaborative multi-dimensional exploration of socio economical inequalities in the industrial food system.
A way to explore a complex system with many actors, and many issues.
To do so, I propose looking at the food system as a volume that can be mapped to different axis to show specific intersections of issues. This by nature is very vast as it can contain as much granularity as desired. For prototyping purposes, three main axis are defined, and a forth would be each food that is run through the tool.
In one axis we can have the agents, and in the other the issues, and even a third with the stages of the food system.
In this way, the project has a potential end-goal, which is to map and uncover all the possible scenarios.
To test this approach, the following entries are selected:
This approach allow us to play with the concept of “volume of possibilities”.
Each “agent” needs to get their own “flavour” their voice. Because each agent looks at the issues from their own perspective.
For the final tool, the particularities of each “agent” and their subjectivity (“their story”) will be captured either with interviews and forms, via interface dials or with presets.
Each interaction ends with a call-to-action. Each agent could define a set of actions and the system would dance around them. ⚠️ Safeguarding setup needs to be implemented to prevent greenwashing/foodwashing, because a main goal of the project is to expose the socioeconomical issues in a friendly engaging un unapocalyptical and blameless manner.
Below, a test run with a 🍋, from a Permaculture local grower perspective focusing on local food culture:
Some other tests with 🥑 and 🍅
Technical development
Since mid October I’ve been scouting for a cool developer to help with the implementation,
and I’m happy to have connected with Ruben Gres
In late December we hosted an intensive work session in the studio to draft the architecture of the digital prototype:

The prototype will take the form of a mobile-friendly accessible website.
Initial development have been made to display a scrollable/draggable endless grid of images on the web.

The backend is running a ComfyUI with Stable Diffusion and a custom web interface collects the outputs.
A workflow to programatically select and mask a given food has also been tested with promising results.
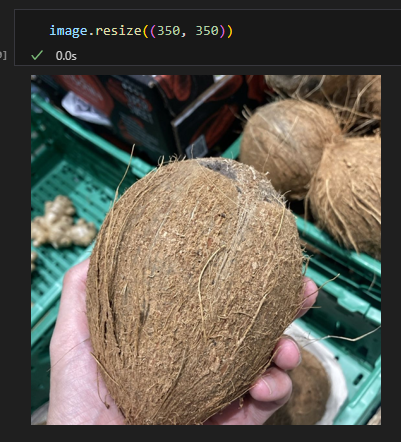
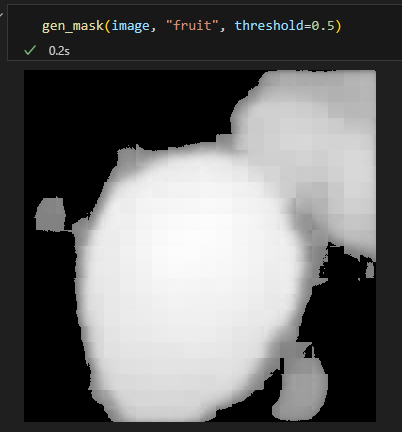
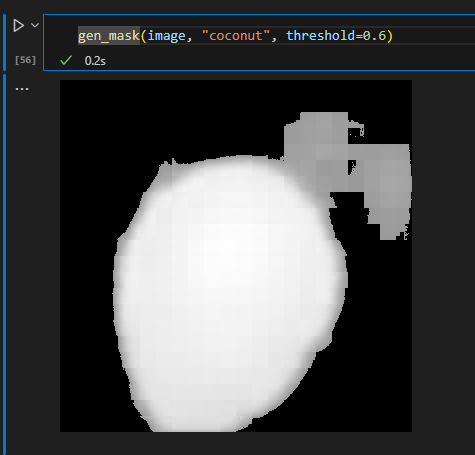
We still need to solve the following technicalities:
integrate LLM generation to drive image creation
store and reference text and images
combine each generation into compelling videos
Next steps from jan-may 24
define the user experience
interaction with the “map” as a viewer
interaction with the “filter” as a generator user
define how to fine-tune each agent’s perspective to the prototype
interviews / dials / presets
develop and implement those decisions
design a workflow to create videos with messages
technical test the prototype in the wild (supermarket, home, printed media…)
stress-test the prototype for failures
re-conceptualizing
call-to-action -> links
The deep dive in technical development triggers some questions that allow for rethinking the conceptual framework.
For instance, the language model (GPT) has to be invoked several times to:
compose the issue (from a set of socioeconomic factors) from a perspective (depending from stakeholder)
create a visual description of that issue: to drive the image generation and morphing
create a call-to-action to propose solutions to the user.
Using this approach we managed to obtain convincing call-to-actions as:
Reduce food deserts: Increase access to fresh foods.
Participate in food swaps: Share surplus with neighbors.
Demand fair trade avocados: Support small farmers and market competition.
Preserve food diversity: Choose heirloom watermelon varieties.
Choose community gardens: Cultivate accessible produce with neighbors.
As a proof of concept, a site was setup to collect early generations of text+imgs, but when seeing all generations at once, some emerge repeat and the call too action seem very repetitive, this is becasue the language model does not have memory of what has said previously, and often uses verbs as “choose”, “avoid”, “fight”…



I had to re-think the role call-to-action and experimented with explicit links for the viewer to take action.
The aim is to get recommendations of resources, associations, media related to the presented narrative.
This works, but often the presented links are the same, a high-level approach as “watch food.inc documentary” or “join the sloow-food movement”.
To add granularity to the generation, I try including location to the query, thus creating site-specific receommendations.
In some cases it surfaces very interesting content, as EU policies on food sovereignty or very specific local associations 👍
This is great because it allows us to go from a moment in reality, straight to a very specific piece of knowledge/data/action.
Results seem good, but sometimes the links are invented, as a Language Model is predictive, the most probable way a link starts is with http: and it often ends with .com or the locale variants. thus, the generated links look ok, but may not be real :(
Examples:
Zagreb, Croatia
Implement a transparent supply chain policy: https://mygfsi.com/
Educate staff and customers on sustainability: https://sustainablefoodtrust.org/
Support local farmers and producers: https://www.ifoam-eu.org/
Lisbon, Portugal
Join "Fruta Feia" to buy imperfect fruits and vegetables, reducing waste: https://www.frutafeia.pt/en
Volunteer with "Re-food" to help distribute surplus food to those in need: https://www.re-food.org/en
Support local markets like "Mercado de Campo de Ourique" for fresh, local produce: http://www.mercadodecampodeourique.pt/
Participate in community gardens, enhancing local food production: http://www.cm-lisboa.pt/en/living-in/environment/green-spaces
To mitigate this, a session with experts from BRNO University was conducted and a change on prompt-engineering design will be implemented, were instead of asking for links related to a content, we might extract content from links. The approach involves RAG Retrieval Augmentation Generation, and empowers the LLM with eyes to the internet.
multiple perspectives
As the whole project is to showcase the different realities of the food system existing behind every piece of food, we explore how to narrate those from different perspectives.
Initially we thought on having interviews or work-sessions with different stakeholders, but later we considered to explore the existing knowledge within a language model to extract the averaged points of view.
Initial perspectives are:
As a wealthy consumer, my purchasing power can influence the food system towards ethical practices by boycotting brands that consolidate power unfairly, mistreat workers, or contribute to unequal food distribution. I support local and cultural foods through patronage and invest in initiatives promoting sustainable economic models in the food industry.
As a supermarket chain manager, I prioritize ethical sourcing and fair labor practices to address power consolidation and workers' rights. We're enhancing food distribution to improve accessibility, supporting local economies to reduce reliance, and promoting local foods to preserve cultural variations. Our sector's efforts include partnerships with small producers and community initiatives.
As a Permaculture local grower, I champion decentralized food production, enhancing workers' rights through community-based projects and equitable labor practices. We improve food accessibility by fostering direct-to-consumer distribution channels, reducing economic dependence on industrial agriculture. Our approach preserves local food varieties, countering the homogenization driven by power consolidation within the industry.
As a CEA industrial grower, we recognize the complexities surrounding power consolidation and strive for equitable industry participation. We prioritize workers' rights, ensuring safe, fair conditions. Our technology improves food distribution/accessibility, reducing economic dependencies on traditional agriculture while preserving local/cultural foods through diverse crop production. We're committed to sustainable practices and solving systemic issues collaboratively.
The generated perspectives could be contrasted/validaded by stakeholders.
Digital prototype - dev
A clear workflow of tools and data is drafted, the prototype will be composed by two clear components:
The reality filter: a mobile-first interface to take a photo in context and experience a narrative of the food system through a morphing video
The perspective map: a navigational interface to sorting and grouping large amounts of media according to similarities
To experiment and develop the reality filter, I tinker with comfyui, whch is a frontend visual-coding framework to integrate multiple workflows related to text-to-image mainly with Stable Diffusion models.
The good side of this is that with this tool I can chain several image generation with conditional guidance processes to create the necessary scenes to compose the video. And I can also pipe some interpolation processes at the end.
For this workflow, ControlNet is key to carry visual similarities from frame to frame. Initially it has been proposed to use depth estimation, but tests proved to be too strong or too weak in different cases, thus experimenting was needed to find another approach.
Using the TILE model gives great results as it is a model normally used for super-resolution, it carries the visual qualities of the source image in the conditioning.
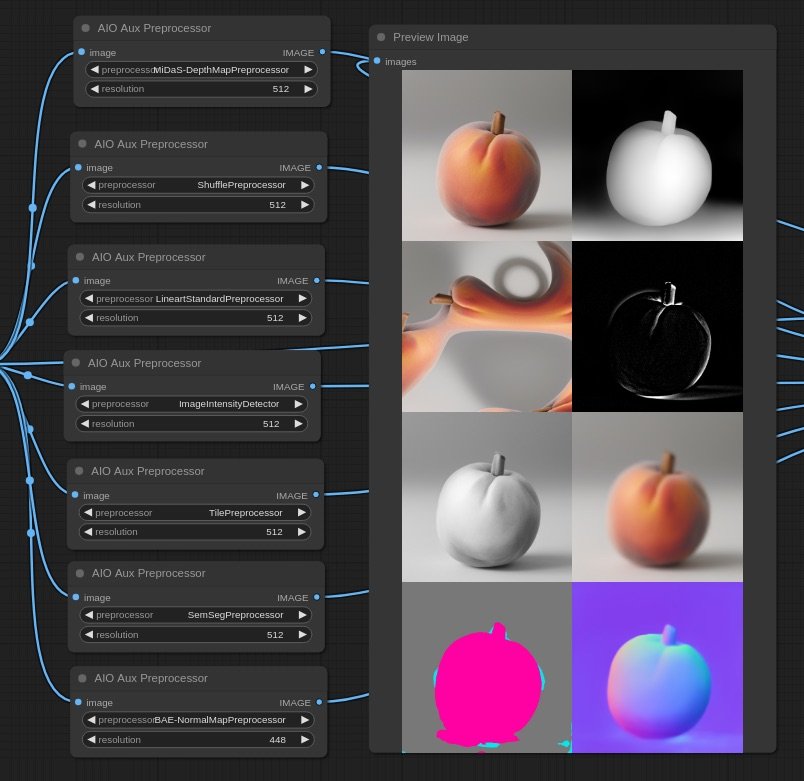
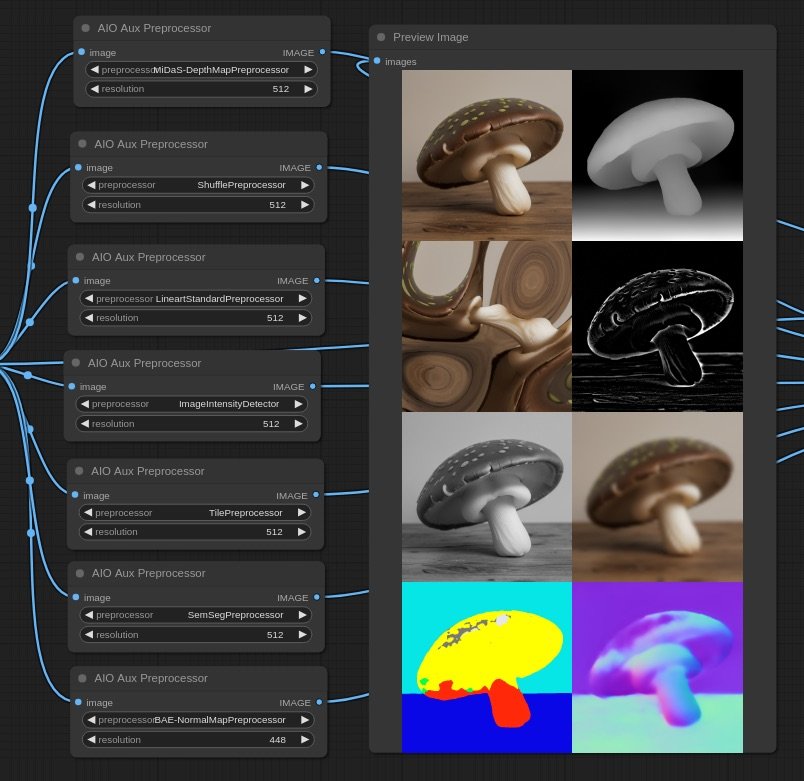
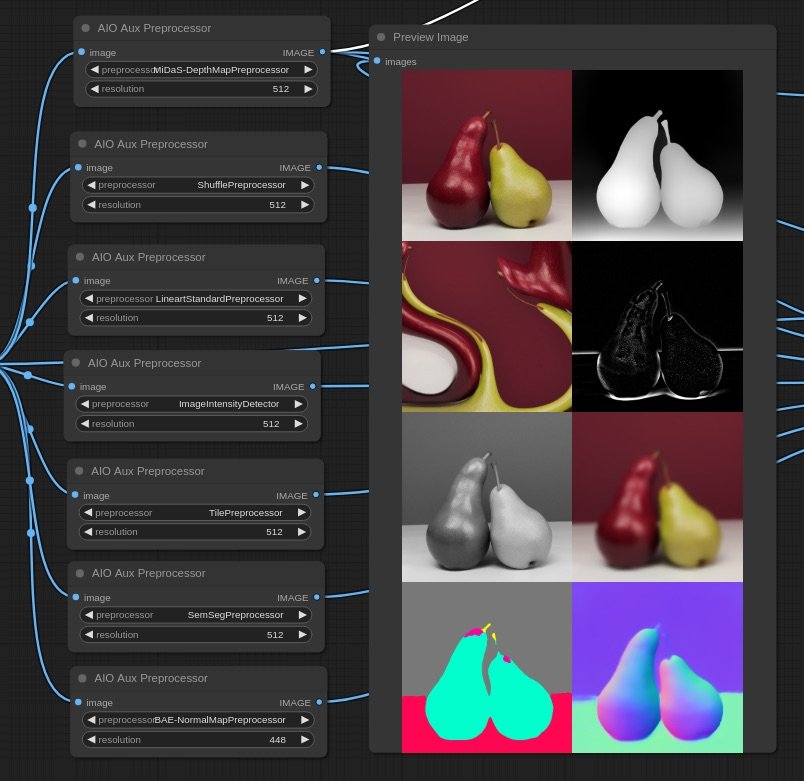
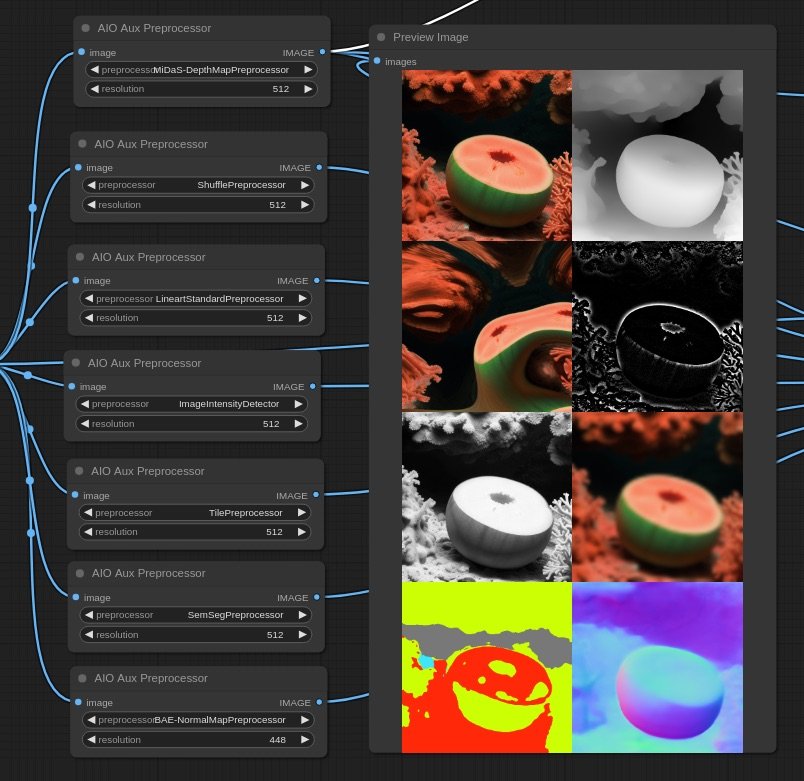
Scenes
Creating new images from starting ones has the following challenge: if the gap is too big, the visual connection is lost, but if the gap is small, we have very few pixel-space to tell a story. So If I want to bring the viewer to a new reality, I need to do it smoothly, and I can achieve this by incrementally decresing teh strength of the initial image in each generation step.
With 4 steps I can already go quite far.






Scene interpolation / video / morph
To craft a smooth visual narrative from the real-world photo to the generated food-system-scene the FILM: [Frame Interpolation for Large Motion] will be used, even if it is quite computationally expensive. There are other approaches, but I feel they break the magic and the mesmerizing effect of seeing something slowly morphing into something else without almost noticing it.
24 in-between-frames seem a good number to create a smooth transition from scene to scene




img2morph -> workflow
videos
samples of the resulting morphs
On the wild / testing
A key advancement has been to find a workflow that allows for experimentation and at the same time use the setup in the real world.
to do this, we use comfyUI as an API, and build a gradio app to be able to use it from a web interface.
Once we have this, we are able to pipe that interface outside the server and use it via a public link, allowing for testing in different devices and locations.
next (technical) steps
*The technical development is done in collaboration with Ruben Gres,. from now on, when I saw "we” I mean Ruben + Bernat
With all the bits and pieces working independently, now we need to glue it together in an accessible digital prototype (within time and resources constrain)
some design guidelines are:
zero friction
app must work without requesting permissions or security warnings
mobile first
the photo taking has to be intuitive and fast - 1 click away
desktop delight
the system should allow for “enjoyment” and discoverability
we are not alone
somehow find a way to give the user the sense that other people went through “this” (the discovery process)
…
Interface prototype
Sorting
Learning about dimensional reduction, I feel this can be a nice touch to use as navigation for the project.
the aim is to find a way to sort the content (media + text) per affinity, or according to non-strict-direct variables.
One approach is using TSNE T-distributed stochastic neighbor embedding (here a good interactive demo). This allows for sorting/grouping of entities according to their distance (embedding) to each other or to a reference (word, image…)
Some examples using this technique is this GoogleArts project of mapping artworks by similarity
We have been able to plot vegetables according to different axis, using CLIP embeddings


grid / navigation / upload / video generation
For the exploration map, an endless canvas with a grid will be used.




getting the right voice / perspective
Testing the whole text-generation pipeline
food -> agent -> issue -> context -> title -> links -> image representation
Relevant links
As the prototype evolves, the ability to provide contextual localized links to events, communities, policies and resources to the viewer becomes more relevant and interesting.
Using the language model, we get beautiful links but that in some cases are non-existing :(
This is an inherent quality of an AI Language Model, as those work mostly as predictive systems, where the most probable word is added after another in a context, thus it is very probable that a link starts as http://www., then include some theme-related words and most likely end as .com or .es .it... according to the location.
This disrupts the prototype, because action can't be taken by the user, and it is frustrating.
To overcome this, the whole structure of interaction with the language model has been changed, and we added eyes to the internet to it 👁️
Using LangChain, and Tavily API , we can request the LLM to search the internet (if instructed) and then analyze the content of the found links and use them as knowledge to build the output.
With this approach, now the language model does the following:
picks up a random stakeholder + issue + food (the photo provided by the user).
Builds up a story around this that hightlights the point of view of the stakeholder in relation to the issue.
Then uses that response coupled with the location of the user (the IP) to search the internet for events, associations or policies that answer a "what can I do about this" question.
The relevant links are rephrased as actionable tasks: "read this... join that... go there...".
Finally a nice engaging title is composed.
to add:
An european dimension : localized content Build for customization: open github repo + documentation + easy deployment (add tech demo video)…
This project is developed as part of the Hungry EcoCities S+T+ARTS Residency which has received funding from the European Union’s Horizon Europe research and innovation programme under grant agreement 101069990. 
This Person Will Not Exist
Photos of people that will die due to climate crisis and anthropogenic hazards.
Photos of people that will die/disappear/vanish due to climate crisis and anthropogenic hazards.


















Not that we need more images of climate collapse and environmental disasters, but since AI is usually used to imagine nice optimistic scenarios, I used it here to highlight the peak stupidity moment we are in.
Inspired by the ThisPersonDoesNotExist site (that served as a StyleGAN demo and triggered an awakening for synthetic media in the general public).
The images have been produced with StableDiffusion, using a combinations of the following descriptive prompt:
"A person in a climate disaster, with (wildfires, flood, drought, pollution, oil, microplastics, waste, misery, technical collapse) / photojournalism photo style”oh, yes, I used technology, electricity and plastic to produce those images, well spotted.
solution? none
remedies? many: stop consuming / stop complaining / start fighting / go forward with nature

DIVIDE
Exposing techwashing to reclaim a social narrative for digital rights and empowerment.
AI + ART for ACTIVISM - digital barriers / EU Project / AI4Future
AI + ART for ACTIVISM - digital barriers / EU Project / AI4Future EXPOSING TECHWASHING TO RECLAIM A SOCIAL NARRATIVE FOR DIGITAL RIGHTS AND EMPOWERMENT
Artwork
The piece explores the multiple narratives around Access to Internet and Digital Divide.
To do so, images from the affected districts are run against descriptive scenarios in a machine-learning text-to-image algorithm.
The artwork is a set of lenticular prints that reveal different narratives depending on the angle that are viewed from, thus showcasing how different people can experience or understand the multiple realities if explored from diverse points of view.
Statement
Access to internet is not equally guaranteed to all citizen, either for the lack of commercial interest by ISP's, institutional and legal boundaries or economical resources. Either way, certain parts of the population see their Right to Internet Access limited and abused.
The activists entity EXO is running a pilot program to provide free Internet Access to affected households in some districts of Barcelona. Their action goes beyond providing internet, and focuses on digital inclusion, stressing that citizen's rights need to be preserved online.
The digital divide appears to be very different depending who is talking about it.
In one hand, the official narrative, the story told by the administration and tech companies, is that everything is fine, that most of the people have access to internet and that sales of smartphones keep rising, thus there's nothing to worry about, we are ready for digital education, digital health, digital banking, digital administration and digital everything...
On the other hand, the social movements indicate that an unidirectional shift towards the digitalisation of citizenship leaves many people behind; from families with one device and several kids needing to do a video-call, citizens who are forced to manage their finances via unusable and data-extractive apps, or households where the internet is shared from a single limited mobile-data-plan.
Digital Divide
🙈👁🤖
Right to Internet Access
👨💻🔒📕
Physical Digital
📱🎒🔌
Digital Divide 🙈👁🤖 Right to Internet Access 👨💻🔒📕 Physical Digital 📱🎒🔌
Glossary:
The Right to Internet Access, also known as the right to broadband or freedom to connect, is the view that all people must be able to access the Internet in order to exercise and enjoy their rights to freedom of expression and opinion and other fundamental human rights, that states have a responsibility to ensure that Internet access is broadly available, and that states may not unreasonably restrict an individual's access to the Internet.
The Digital Divide is a gap between those who have access to digital technology and those who do not.[1] These technologies include, but are not limited to, smart phones, computers, and the internet. In the Information Age in which information and communication technologies (ICTs) have eclipsed manufacturing technologies as the basis for world economies and social connectivity, people without access to the Internet and other ICTs are at a socio-economic disadvantage because they are unable or less able to find and apply for jobs, shop and sell online, participate democratically, or research and learn.[2]
Work in Progress / notes
(chronological order -> new at the end)background
AI4Future is a Creative Europe’s project which involves three different European countries: Italy, Spain and Netherlands. It aims at enhancing the understanding and dissemination of AI related technologies for the active and creative participation of young activists to the European cultural scene, allowing them to work with artists for a joint creation of a new urban community awareness.
barcelona chapter / partners
Canodrom: Open technologies, participatory democracy and digital culture
ESPRONCEDA Institute of Art & Culture: international platform and multi-disciplinary environment for artists, curators

dev notes About eXO’s project: Open Networks for Digital Inclusion in Neighbourhoods / presented by Efraín Foglia
2022/2/3 - hello project / Discussion with @canodrom and @espronceda to know their ongoing projects and draft collaboration framework
We learn about the Xarxa Oberta de Barris, (open-networks-in-neighbourhoods), a project by Expansió Xarxa Oberta / eXO, aimed to facilitate the right to internet access by bringing quality internet to families in Sagrerea/Congrés-Indians in Barcelona who have vulnerabilities in their internet access.
Within the project then, Canodrom becomes the facilitator, eXO the activists and the families the citizens.
the citizens / the project is looking for people with vulnerable internet access
drafting ideas / following the initial proposal, the aim remains to visualize and explore.
eXO’s works with hardware, with physical stuff to enable internet access. Since internet is usually visualised as ethereal clouds, it is interesting to go back to the tangible world and work with the stuff that make this possible.
As we will be working with families with vulnerable digital access, I’m curious to understand the expectations, what are the words, concepts associated to the digital world and the internet. I cold work with the families and the activists to
v0.1 “Possible landscapes made of cables”
Artwork: A Panorama image made with "internet hardware", blending with AI-generated images from the community's description of "internet".
technically: Using ALIS as a generative GAN fed with images of cables, routers and devices. And using a Text-to-Image algorythm to visualize internet-expectations from the community.

proof of concept / v0.1
Testing models and datasets

Proof of Concept - 000 / collecting random cables and boxes
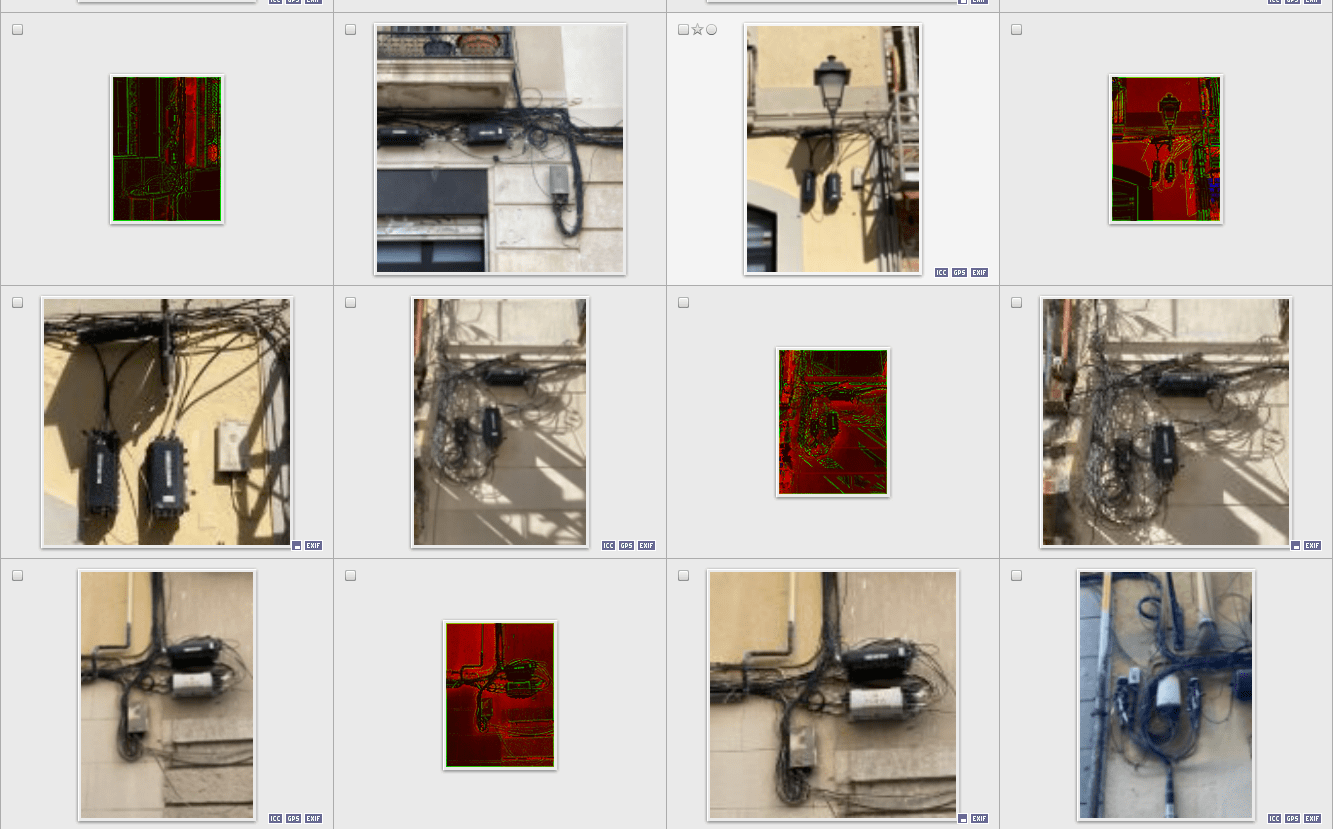
cropping by region of (algo)-interest






2022/03/01 defining collabs: discussing the approach with Espronceda & Canodrom
avoid the parachute effect, where a project lands in a context, extracts and does not return
in this project, the artists is a resource for the activists to use AI as channel to approach a challenge
the goal of the AI4Future project is to see how AI can empower activism.
The focus should be on the process, more than on the piece.
2022/03/02 preparing an upcoming event at Rotterdam V2 with the other artists in residence - Nino Basilashvili / Chunju Yu / Luca Pozzi
proof of concept 02 / internet as a visual representation
digesting the visual qualities of popular image representations of “internet”.











2022/03/04 session with the local activists / understanding their vision of the issue, the concerns and the potential
This project is key as a legal framework, because in Barcelona it is not allowed for citizens/associations to provide internet to other citizens.
There’s a dissonance between the official narrative and what’s happening “on-the-ground”
Digital divide is politically understood as infrastructure
There is a layer of WASHING where “technology” is equaled to “accessibility” thus painting a picture of tech-enabled city / (TechWashing/SocialWashing)? / with possible redlining
Access to Internet is not guaranteed, as it is left to corporations and their market-driven-decision-making, and pushed to the individuals requiring paid connections and updated devices.
Beyond “going-online”, citizens must have their rights granted while online
Majority of services are switching to online-mode, leaving behind who does not follow (skills, disabilities, legalities): banking, education,
There is an opportunity to re-write the narrative, the concepts, the words.
There’s a gender gap within the digital rights activism
Mapping the actual project could also visualize what’s the local reality
i.e: there’s a high concentration of internet-cafés in that specific area (laSagrera / Congrés-Indians), probably a sign of poor home connectivity / lack of devices or help.
There’s a practical challenge to find candidates for social projects as their detailed realities are unknown for the administration or activists (ironically, that information is well known by BigTech/GAFAM)
Whatever we make, should not just TALK about the issue, but be INVOLVED with the subject and add up instead of taking.
Other considerations:
Local sites for on-the-ground action: Espai30 / canodrom / public space
official narrative / BarcelonaDigital: digital transformation - digital innovation - digital empowerment
v0.2 /
Digging into the idea of Double-Narrative, I’m cooking a process/piece where we’ll define which are those narratives and how they shape our perceived reality.

Why:
Expose tech-washing and reclaim a narrative of digital rights and empowerment.
Work with the activists to define what’s wrong about the official narrative and what’s under-looked



How:
Side by side comparison of the same location, visually shaped according to two opposite narratives.
Use text-to-Image algorithms to visualize the transformation of spaces according to specific descriptions of reality.
Use Barcelona’s open image datasets
Use maps built with BarcelonaOpenData datasets




proof of concept / Plaça de Masadas - Sagrera (initial image by Vicente Zambrano, for Barcelona gov)
left: “a smart city inside the metaverse, cyberspace style”
right: ”piles of e-waste and old electronic devices”
What:
A multi-viewer non-linear artworks that can be placed in multiple settings.
Lenticular Prints that allows for a low-tech experience while giving a sense of transformation and exposing different realities depending on the viewing angle.
Bringing the digitally AI-created images into the physical realm
A (growing) list of double-narratives built with conversations with the activists and literature review
The mediaCatalonia is a leading “Digital Country” in EUTelecommunications is a citizen's rightBlockchain technologies for digital democracyApp-based healthcare systemBarcelona as a technologically advanced cityInnovative digital education platformsBigTech trade fairsFunding of new technologies like the metaverse and digital currenciesBarcelona is a fully connected cityIn 1997 the public company Telefonica is privatised and inherits the existing physical infrastructure, and rents it to other ISP's. From 2008 any company can build their own optic-fiber infrastructure (companies rush to take profitable markets like big cities (often over-installing) and ignoring other parts of the territory).The Goverment starts a publicly owned optic-fiber installation (XOC) with regulated prices. (11 years after the announcement, only arrives to 32% of the municipalities, connecting government sites, not people). The network is run by the main ISP and does not allow small operators to connect to or use it at a fair price....
The peoplemore than 50% of the population in Catalonia does not have access to broadbandThe infrastructure that allows telecommunications is a resource to speculate withISP's do not have commercial interest in providing internet to everybodyDigital divide affects specifically to traditionally excluded populationsHow can someone have access to digital health if can't afford a data plan?How can digital education be fair when access to technology isn't?BigTech fairs exclude the social agenda.Digital rights are an extension of human rights in the digital domainNot all neighbourhoods have the same infrastructureA better and more efficient optic-fibre installations would lower the costs and provide better services by using bandwidth surplus.It is technically viable to provide internet to any part of the territory.Internet is a technology that can be run and managed locally without a speculative approach.Networks as a commons ...
Rotterdam / worksession / mid march
We met with the other artists at V2 - {lab for unstable media} / Rotterdam
to discuss the scope of the projects, review development and share technical approaches.
We put together a dev-show to share directions and get feedback from visitors.
v0.3 /
Technical approach
The project will pivot around CLIP (A neural network called CLIP which efficiently learns visual concepts from natural language supervision. CLIP can be applied to any visual classification benchmark by simply providing the names of the visual categories to be recognized, similar to the “zero-shot” capabilities of GPT-2 and GPT-3. / 400.000.000 images)
CLIP’s capacity for semantic processing will allow the project to process the narratives around Digital Divide.
CLIP code https://github.com/openai/CLIP
For Image generation, DDPM (Demonising Probabilistic Models) will be used. Specifically Guided Diffusion models like GLIDE
When combining CLIP + DDPM we are able to create a Guided Diffusion (paper), where a loop happens between imgs < - > text.
An example of guided diffusion is DALL-E or GLIDE, or RUDALL-E (paper)
With the stated tools and models, a workflow will be set up to input an initial image and a prompt i order to generate an output image as following:

Being a “words & pixels” approach, a certain focus needs to be put on Prompt-Engineering: when words, descriptions and meanings need to be carefully selected to craft the direction of the output.
below : keywords comparison image grids for the CLIP + VQGAN workflow to visualize the effect of different styles/descriptions applied to the same concepts. (more grids here)






Localisation - The activist’s project will be implemented at El Congrés i els Indians neighbourhood of Barcelona.
In order to collect visual material for the project, a field study was conducted in early April.
A photo-tour capturing localised infrastructure, spaces, housing and elements.
The results of the fieldwork will be the starting point for the AI workflow




















dev v03 - images & prompts

Testing some prompts in the workflow in order to explore styles and visual languages.
starting from generic concepts of connectivity, and narrowing towards detailed descriptive scenarios.
crosstests: different prompts and workflow settings











Curating samples:
Combinations of settings, prompts and source images proved to be interesting while others lack detail or effectiveness.
A CONNECTED CITY, WITH INTERNET FOR EVERYBODY WITH EFFICIENT DIGITAL SERVICES
A CITY WHERE CITIZENS ARE IN A DISADVANTAGE DUE TO OBSOLETE DEVICES AND POOR ACCESS TO INTERNET
Prototype:
Printed prototypes using lenticular technology will be produced in order to test the visual quality and desired effect.
V04 / understanding activism
A workshop session was run with EXO and Canodrom in order to explore and define the narratives that will drive the final artwork.

raw concepts:Open and neutral free network for everyoneDigital culture, free technologies and democratic innovationCitizen governance digital democratic participationOpen KnowledgeTransparency and open-dataPublic money for public codeConstruction of community infrastructuresJoint networkThe Internet as a place for human rightsInclusive networkRadical participatory democracy.eGovernment as a digitalization of democratic and participatory processes. (desired)eGovernment as a digitalization of the status quo. (what is happening)The system phagocytose and naturalizes radical movements.Ideological extractivismNeo-conservative vampirismTechWashingSurveillance capitalismBigTechs are amoral, they only position themselves in the band that brings the most profits.Software sophistication widens the digital divide due to lack of knowledge.BigTechs feed on the dependence of users and institutions on their software.Alternative initiatives cannot be equated with the service and usability standards offered by BigTechs, creating a barrier to the adoption of new ideas and ways of operating on the Internet.There is an intentional complexity to online services, blurring responsibilities and positioning the user as responsible in the event of an error or event unfavorable to the company.When banking is digitized in the name of efficiency and better service 24/7, the company gets more profits and more responsibilities are transferred to its users.The algorithmic complexities of digital services are used as an excuse by companies and administration to offer services without guarantees or transparency.SmartCity has not meant any visible improvement to the city's main problem, which is housing.The administration does not allow to act with the communication infrastructures.Some government projects approach digital rights with a paternalistic approach to helping the needy.There is the opportunity to do community work and train the population for digital autonomy.The government allows it and promotes private companies to own the communication infrastructure.The initiatives that are encouraged are only in the field of services, such as Apps and StartUps.The cost of network access: When choosing between having internet or food.A citizen without internet is excluded from public participation, leisure and the relationship with the administration.Internet access is necessary and not optional, but it is not treated as a fundamental right.Historically, the Internet has appeared after large infrastructures have already been privatized, so it is not even considered to be a public good and its implementation and management is quickly awarded to the private company.

The concepts were organised by themes and a set of narratives extracted to drive the AI workflow:.
The Alternative Narrative:
Apps and digital services are intentionally opaque to confuse users and avoid responsibilities.
Corporate practices should be auditable and companies held accountable for bad practices
Smart City has not solved the housing problem
The Official Narrative:
New apps and services make life easier and more efficient.
Corporate information and operations need to be kept secret in order to offer good services and apps.
Smart City bring prosperity and the future to everybody.
New media has been created using the above descriptions
physical artwork
Exploring the lenticular printing process, it is possible to show multiple frames form different angles.
Tests with different resolutions and frame combinations have been tested.
Professional prints have been produced as exhibition pieces.
To make the artwork self-explanatori, a video will be produced to introduce the activist’s role and the tools used to produce the visuals.
Since all the media used is square 1:1 ratio, which is a common ration for Machine-Lerning models, the explainer video will also be square, and displaeyed in a square display, mounted inside a frame.
Exhibition in Barcelona
As an extended program of the International Symposium on Electronic Art a preview show was organised at Esproceda’s space.
A joint exhibition with LEONARDO organisation, Aalto University and the AI for Future Project, as part of the New European Bauhaus Festival

Technology update
In February 2022, when this project started, the most suitable tech approach for the artwork idea was image generation with CLIP and Diffusion models, a good implementation of this technique is DiscoDiffusion (A frankensteinian amalgamation of notebooks, models and techniques for the generation of AI Art and Animations.) info + video tutorial
All the generated images of this project have been made using variations of that code.
During the past months, many advances occurred in the space of text-to-image generative models; including public access to Dalle2 by OpenAI, the promising Imagen by Google Research, or the popularity of MidJourney.
One key event is the open-source project Stable Diffusion:






This technological update is fantastic, but it comes a bit too late for this particular project, so I stick with the original tech setup to finalise the artwork.
Here is a test of some of the "narratives" from this project run through the new model:
v05 / a large scale piece
With the fantastic results obtained with the pieces produced for the barcelona exhibition, it is proposed to develop a new large format piece.
A new round of photos were made onsite, with special attention to the quality of the center image, looking for a photo that reflects the characteristics of the territory while captures certain aesthetic qualities.






More photography tests were done using a fisheye lens, hoping for an immersive and captivating point of view.



The prompts/narratives were also fine-tuned to extract/distill visual qualities.
The new sets of photos were run again through the same AI system, producing novel and mesmerising results.





survivors of the curation process:


The large 100x100cm piece will be produced with the following images:
Exhibition at Canodrom / Oct-Dec 2022
In order to bring the piece closer to the community, a 2 month public exhibition was organized at Canodrom, including an open guided tour during a community meeting of the families that participated in the XOB initiative.
sidenotes The role of AI treat AI outputs and predictions with as much authority as the ones of fortune teller: biased subjective predictions based in the past data and assumptions / Algorithms as cartomancy – Schemas of Uncertainty
Datasets Research into OpenData BarcelonaThere are some datasets about infrastructure / internet access: Wifi hotspots of the city of Barcelona / List of services companies in the city of Barcelona / Main housings of the city of Barcelona according to facilities III : telephone-internet
Barcelona images / a collection of images that (officially) represent Barcelona
references / projects / artworksThe Future of the Last Mile / Wireless Mesh / article & podcastUltima Milla / Documentary on the effects of speculation on the fiber-optic business in Catalonia video (cat)Cloudplexity / visualizing internet/cloud in patent applications / artwork Mario SantamariaSmall c vs. big C: How Computational Infrastructures capture technical and social imaginary for public life
Artwork created thanks to the production grant by ESPRONCEDA-Institute of Art & Culture, within the European project AI4Future
VOLS
Interventions in the public space,
without permission, without atoms.
💬 work in progress - developmentInterventions in the public space, without permission, without atoms.
exploring technologies, tools and approaches to experience digital content in the physical world.



Background / Motivation
The Weight of Stuff
While working with 3D, I’ve always been seduced with the idea of bringing the content out of the screen, hence my sizeable experience and affair with 3D Printing and digital fabrication… But I don’t feel a pressing need for turning bits to atoms, I can’t find a reason to go through all the resource consumption and physical nuisances that such endeavour entails. Physicality is overrated.

I come from a product design (industrial) background, where stuff is designed to be made, and I feel I’ve developed a sensitivity towards stuff, matter, geometric volumes, materials and finishings. With such eye for the built material environment, I do appreciate and I even find joy in observing stuff, admiring the shape, materiality and mechanical solutions used to solve physical challenges. I’ve devoured countless pages of “design magazines” (I even ran a “web-ring” devoted to product design back in 2006)… I like objects, I like stuff that is expressive, products that go beyond the average intentional mediocrity of mainstream mass produced instant-junk. I do admire and appreciate the classics like Eames furniture, the contemporaries like Marc Newson, the works of the Bourollec Brothers, or the lamps of Patricia Urquiola…
I know their designs from images, videos and photos… but I have NEVER seen IRL, used, touched or owned any of their designed products…. , but I like them, very much.
What am I in relation with?… with the object? or with the idea of the object?
If stuff does not need to physically exist to be enjoyed, can can I just experience the idea of a creation?…
so… should I make stuff? or just design it?
This project is an attempt to do that:
Design without making; enabling the experience of volumes, without having to materialise stuff.
Technical approach: Augmented Reality
Augmented reality (often known as AR) is a computer technology that shows digital images on top of the current real world. For example it can show a digital table on top of a floor. It is different from virtual reality which makes a person feel they are somewhere else.
Vectors of interest
The Scale
I’m interested in the perception of scale allowed by augmented reality.
The built environment operates in a human scale, where the larger scales belong to infrastructures (bridges, damns,..) and architecture (buildings, public spaces…) while objects are at a smaller scale, (from paperclips to refrigerators). Placing something to the world of a significant scale is ecologically expensive.
With AR, it is possible to overlay volumes at any given scale.
The Public Space
As a place where interventions are forbidden or reserved to a selected few. Stuck in between the no-places and the privatisation of the public space, individuals have a very few channels of modification of public space.
The Private Experience
Within the intimacy of our devices, we exist in public (metro, street, mall…) while having a very personal, unique and secretive activity: what is happening on our screens.
This allows for experiencing something very personal, and unique to the individual (location, point of view…) while interacting in a public space with other entities
AR as a channel / tests
🧑💻 development notes<modelviewer>:new version auto-generates USDZ files for iOSauto-generated USDZ files do not trigger iOS quick-look in Chrome :(
3D model preparation in blender:USDZ export add-on des not generate proper files for iOSto use transparency textures in a .glb, the material needs to be set to alpha-blend.bake the material if contains generative textures, and build it again before exporting.only in Cycles / w CUDA (OPTIX not supported)
Animations generated by keyframing modifiers (i.e displacement) won’t export to .glba) convert selected keyframes to shapekeys and interpolateb) export model as .mdd and import it again = vertex positions will be turned into shapekeys, 1xframe! = model size * n frames[ ! ] USDZ does not read shapekey animations :(
GLTF / USDZ specifications
animated materials won’t show
potential workshop
Augmented Photography
Workshop to design and add digital creations to the physical environment as triggers for experimental photography.
Using Creative 3D modelling and Augmented Reality for street photography.
In this workshop we will create 3D volumes, export them as valid .gltf files viewable on the web, and prepare them for being launched in Augmented Reality via smartphone.
We will then go out with our freshly created AR models and run an augmented photo-session in the public space, capturing the best angles and shaping the environment at our wish.
participants
ideal for creatives who want to experiment building basic AR experiences in the public space.
Photographers / Architects / Designers / Creatives
No prior knowledge of 3D is required
motivation
This workshop is a sharing session of the current work being developed by the artist, where he is creating Augmented Reality installations in the public space as a tool to modify the environment without asking for permission and without using atoms.
learnings
build basic 3D models
make 3D models accessible via web
enable augmented reality on the phone
take photos / videos in AR
tools
blender for 3D modeling
modelviewer for publishing on the web and AR
Android’s Scene-Viewer to view AR
iOS Quick-look to view AR
requirements
BYOD - bring your own device:
laptop with Blender installed
cellphone / Android or iOS
Workshop Outputs
photographies of digital 3D models taken in the physical public space.




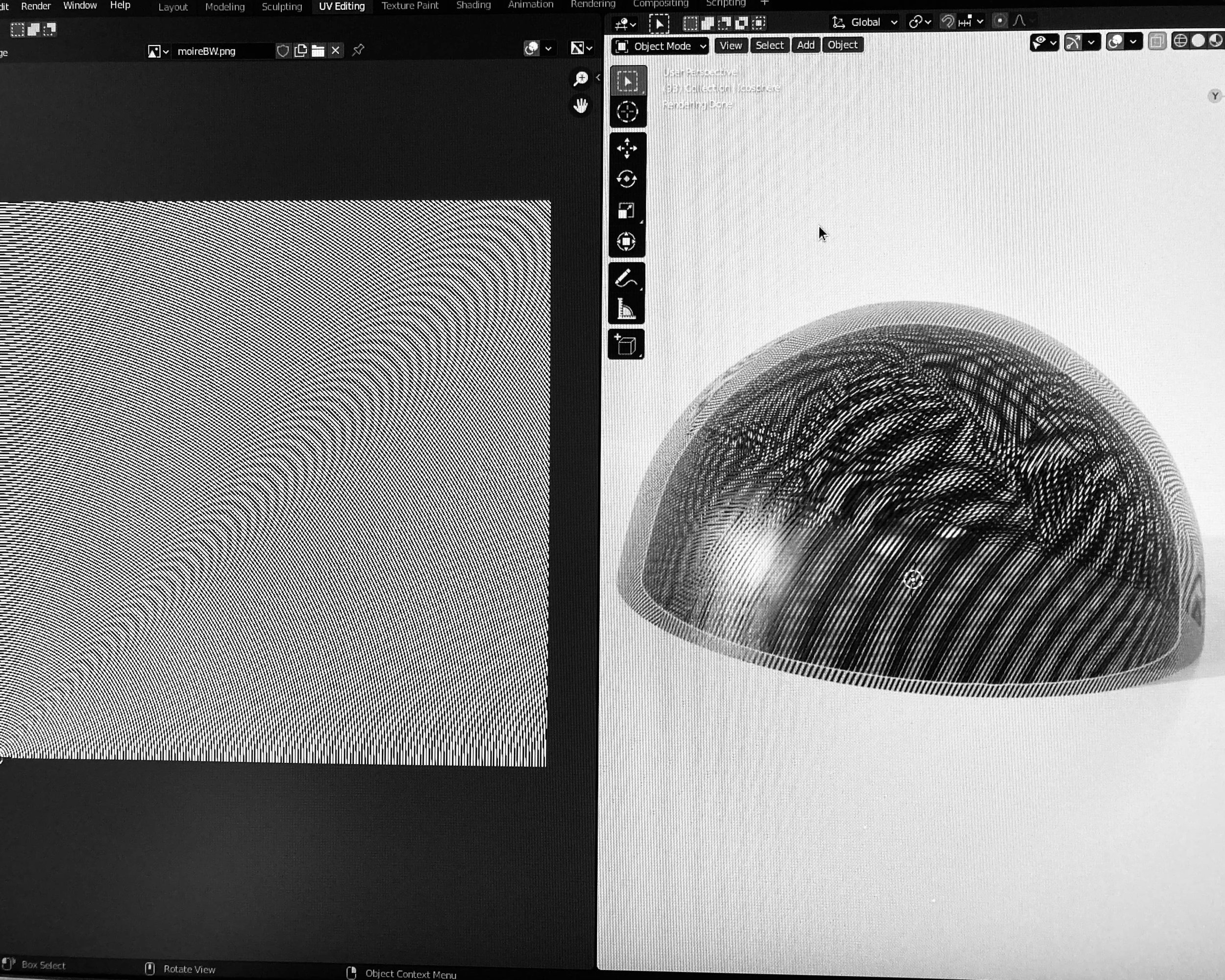




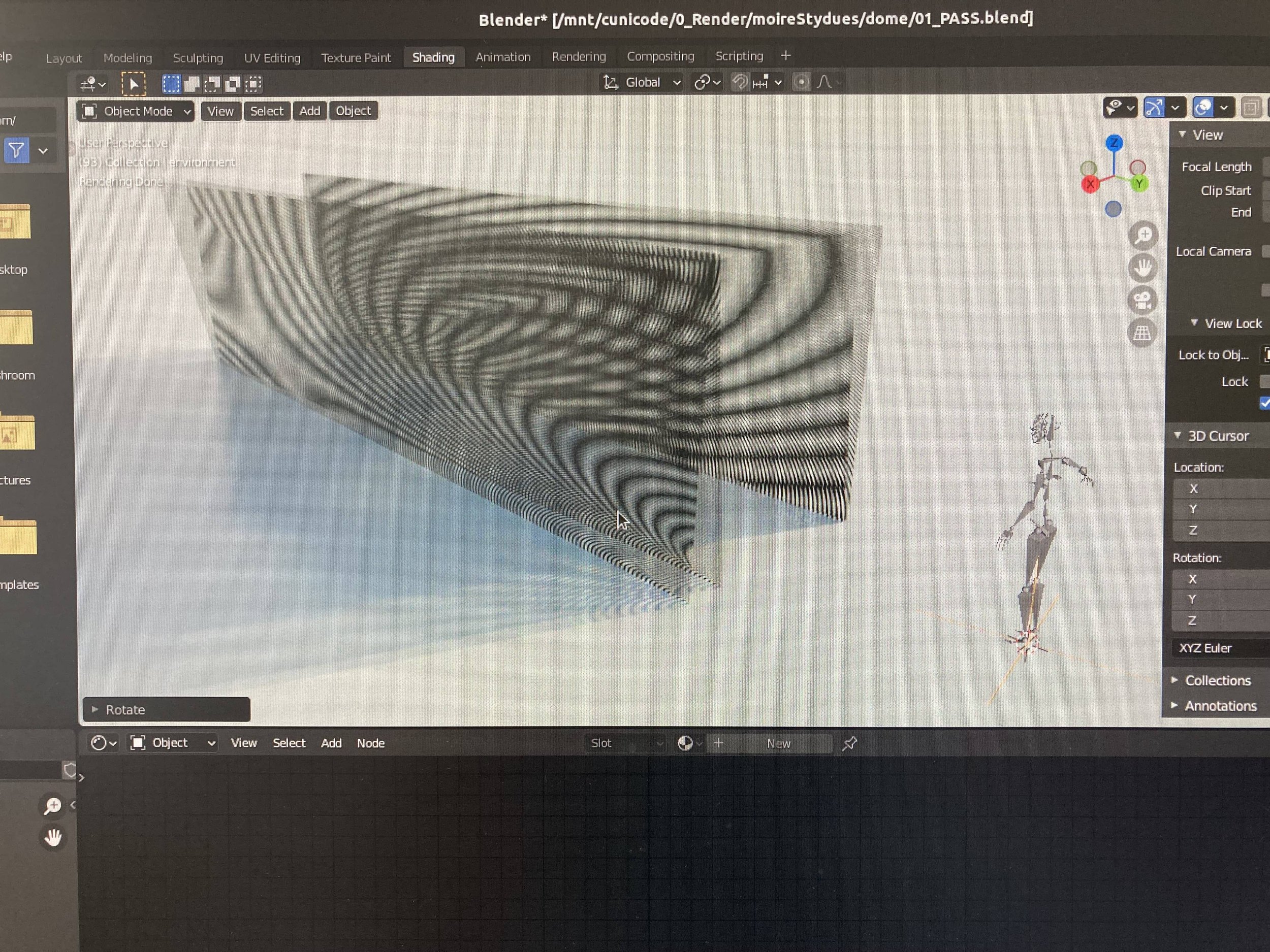



Landscapes
Populating a publication of post-human thoughts with bacterial sceneries.
Populating a publication of post-human thoughts with bacterial sceneries.
A collaboration with Estudi Bicoté for @CARN_de_CAP



CARN DE CAP is a yearly literary publication by escola bloom
For this issue #3, they asked 12 authors to think creatively about the imaginary and speculative landscape of posthumanism.
Contents:
Paraula de l’editor: Paisatges POSTHUMANS – Borja Bagunyà .
Paraula de l’editora: el futur serà avorrit – Míriam Cano.
Fedra (o els arxius) – Víctor García Tur.
Lo más parecido a la felicidad – Ana Llurba.
Dead home – Roc Herms.
Como una cabeza enloquecida vaciada de su contenido – Patricio Pron.
Un conte que no és per a tu – Irene Solà.
CODEX pOLYPHONIK – Max Besora.
Inmuno – Francisco Jota Pérez.
Nervios como arbustos de coral – Regina de Miguel.
El congrés de Palerm – Joan Benesiu.
Com el temps – Lucia Pietrelli.
Muntanya màgica – Aleix Plademunt + Borja Bagunyà.
To package such content, they invited Julia Francino and Maialen Arana from Estudi Bicoté to design the publication itself, (as they previously did for book #2 and book #1.)
Together with Bicoté we explored ways to involve some kind of AI in order to tell a story of post-humanism…
Some initial ideas included, creating a unique font for the magazine, machine-learning the texts and create a new piece….
Soon we put together the concept of bacteria, as a living organism the precedes humans and will outlive them.
Test 01: AI generated bacterias.
We gathered some hundreds of images of bacteria (and small things), and created a dataset of 1500 (by augmenting it via cropping, rotating and mirroring the original images).

I used Stylegan2 to train a model capable of generating novel images resembling the originals.
The results were beautiful, and the generated videos, mesmerising.

but there was a problem; the images looked too much like real bacterias, without an expert eye, the viewer might be confused to believe that those were actual images of bacteria.
It was challenging to tell the story of AI-generated bacteria with those images, because we’d have to spoon-feed the viewer into the concept, so that path was discarded.
Instead, we speculated with the concept of landscapes, as territories where possibilities and stories happen, and as permanent and permanently changing entities that existed before humans and will be present in a posthuman scenario.
Test 02: Breed bacterias in the wild
Exploring the concept of transfer-learning, (where a trained model is used to train a new one), I took an existing model of realistic landscape photographs and used it as the starting point for training a new model of bacteria.
During the early iterations of transfer-learning, the model takes features from its origins (landscapes) and tries to generate images resembling the new dataset (bacteria), the results are interesting in-betweens that neither look like landscapes nor like bacterias but have visual qualities of both.

I tried both ways:
landscape -> bacteria: somehow landscapes predominated and created imagery with the shape of bacteria grows that resembled satellite images.
bacteria -> landscape: it kept the textures and colors of the bacterias, but with the shape of mountains and valleys.
best results were obtained learning landscapes starting from the bacterial model.

Bacterial model trained with landscape dataset

Landscape model trained with bacteria dataset
This triggered the team and we ran a curatorial session to select the candidates from a pool of 2000 generated images.















Results:
With this material, Bicoté decided to spread it through the publication in a circle-shaped fashion resembling petri dishes.

Sketch to Color - AR/ML - Lens
Drawing Colorisation Lens / Augmented Reality & Machine Learning / creator residency @Snap
A camera lens for Snapchat aimed to point at a drawing and use machine learning to colorise it.


detailed video ->
the same, 90% longer
Project developed as part of the AR Creator Residency Program at SnapChat - a global initiative designed for artists and developers to explore new ways to bring their work to life with augmented reality.
Using the Lens Studio software and the Machine Learning component.
Behind the Scenes
initial thought: develop a lens to colorise drawings.
(without having no idea how to do it 😅)
Previously, I've seen some web-based applications that use machine learning to do that. So, initially, it shouldn’t be hard to make it run on the camera, as a lens.
AI-Powered Automatic Colorization / https://petalica-paint.pixiv.dev/index_en.html
Initial research pointed me to the Styles2Color repository which does exactly that in great detail. Unfortunately I was not able to make it run, and I had to look for an alternative.
I choose Pix2Pix because it is well documented and seemed like a good solution for the task. I set up on my local machine with this repository by Jun-Yan Zhu and started the testing.
First I had to find a suitable dataset of image pairs, linework -> color, so Pix2Pix could learn how colorized images should look based on a source line drawing.
I found it at Kaggle: Anime Sketch Colorization Pair is a 14k images dataset of Anime drawings (quite NSFW).
Trained Pix2Pix up to 200 epochs, and results were convincing.
But, I hit a roadblock when seeing that the model file generated was over 200Mb, which is an impossible size for fitting it inside a mobile lens :(
Luckily, with the support of Snap team, I was pointed to the work of Char Stiles who previously did a residency and developed a “Statue Lens” using Pix2Pix as well and managed to shrink the model size to 1.1 Mb.
Using her code I trained the model again, and results were surprisingly good.






While the model was working nicely with line drawings, it produced weird outputs when pointed to non-drawings (obviously).
so using Edge-Detection from LensStudio’s Post-Effects library I could try to stylise anything into a line-drawing.
Adding the model to LensStudio is quite straightforward if starting from a SnapML template.
I started with a StyleTransfer lens, and imported the .onnx file with its corresponding Scale and Bias settings.

For the User Interface I opted for something clean and monochromatic to mimic the comic/mange look & feel.
I designed a square canvas to accommodate all kind of screen sizes and placed the 1:1 ratio camera in the center.

layout composed with indistinguishable comic fragments
Since the model behaves very differently if the source image is a drawign or a fake-edge-drawing-style-realworld-image, I had to offer the user the chance to change the effect applied to the camera depending on the usage. To do so, I placed two previews grayscale/edge for the user to choose and use whichever feels better.
User Interaction / Interface layout

Before continuing, a next round of tests was done to try to improve the model’s behaviour.
It appeared that the camera noise was making the model loose the sharpness and color richness I was getting when running it locally.
To try to solve that, I augmented the dataset x4 by adding noise, blur and grayscale versions of the original image-pairs.
Results did not improve dramatically, so the original model was used to build the final lens.



Final touches affected the layout of the user interface because once the lens was published the top part of the screen became unresponsive to touch, rendering the grayscale/edges previews unusable. :(
A workaround was to move the affected elements a bit down, covering the main element, a design decisions that makes the whole interface more crowded but makes it usable.
The ui elements disappear once the user is happy with the results and taps the snap button, resulting in a clean comic-like page with the colorized drawing cantered in the middle of the screen.



Download lens
Sketch to Color / @cunicode
credits & thanks:
model: CycleGAN and pix2pix in PyTorch
code tweaked for SnapML from Char Stiles
dataset: Anime Sketch Colorization Pair / kaggle
support from snap team: Olha Rykhliuk - UX / Aleksei Podkin - ml
Tests & FAILS




























C is for CAT 🐈
Exploring machine's ABC's / image datasets



Exploring machine's ABC’s
Digging into tools for machine learning (ML), I found that there are some publicly available datasets that are commonly used for training ML tools that surround us.
This is fascinating and scary.
Those datasets contain weird stuff... and those are the building blocks of the tech that takes decisions for and on us.
One of those popular datasets is COCO (common objects in context). (build with using people’s Flickr photos, with their legal consent, but probably without their knowledge)
By curiosity, I started digging the 42,7 GB of images from the COCO dataset, where you can find 330K images containing over 1.8 million objects within 80 object categories and 91 stuff categories. 😱
-> here some wonders found inside COCO-VAL2017 dataset : 🤦♂️












*I personally do not find myself identified with the look & feel of the COCO dataset... my food does not look like that, my living room does not look like that, my hometown dos not look like that... and so on...
👉 explore the COCO dataset here
COCO Categories: person / bicycle / car / motorcycle / airplane / bus / train / truck / boat / traffic light / fire hydrant / street sign / stop sign / parking meter / bench / bird / cat / dog / horse / sheep / cow / elephant / bear / zebra / giraffe / hat / backpack / umbrella / shoe / eye glasses / handbag / tie / suitcase / frisbee / skis / snowboard / sports ball / kite / baseball bat / baseball glove / skateboard / surfboard / tennis racket / bottle / plate / wine glass / cup / fork / knife / spoon / bowl / banana / apple / sandwich / orange / broccoli / carrot / hot dog / pizza / donut / cake / chair / couch / potted plant / bed / mirror / dining table / window / desk / toilet / door / tv / laptop / mouse / remote / keyboard / cell phone / microwave / oven / toaster / sink / refrigerator / blender / book / clock / vase / scissors / teddy bear / hair drier / toothbrush / hair brush
So, intrigued by "how does stuff inside COCO looks like", I ran a segmentation model MASK_RCNN through it to extracted thousands of items of each classification:
The images found are weirdly beautiful...
A is for Airplane ✈️


















B is for Banana 🍌


















C is for Cat 🐈


















D is for Donut 🍩


















...
and of course, P is for Pizza 🍕


















⚠️ People make datasets -> Machines learn from datasets -> machines take decisions based on their learnings -> decisions affect peopleBuild your datasets,
defend diversity in datasets,
fight for non-biased datasets,
there's always a human to be made accountable for machine errors.
Remember when there's an issue at the bank/store/insurance and some staff tells you "oh, there is a computer error, I can't do anything about it"… well, that's a cheap excuse; computer errors rarely exist, those are mostly human errors made by the human that programmed the thing, the human that installed it or the human operates it.
and.. bad news, because things are about to get worst with Machine Learning and Artificial Intelligence, as more decisions are delegated to seemingly inscrutable algorithms, you or your actions can be easily mislabelled, and then, it might be very hard to prove the machine wrong, because we know how to program AI, but we don't really know how/Why decisions are taken within the AI. 🤷
👉 Get a nice C is for CAT 🐈 poster here ->

CAVE
Non-existing cave paintings created with StyleGAN from 2k real images mostly from Chauvet and Altamira



A digital art project that bridges the ancient past and the present through the power of artificial intelligence. The gallery showcases non-existing cave paintings, each one a unique creation of StyleGAN, a generative adversarial network trained on a dataset of 2,000 real images from the renowned Chauvet and Altamira caves.
These digital paintings are more than just images; they are a testament to the enduring human spirit of creativity. They serve as a reminder that the people who painted the original cave walls, biologically identical to us, used art as a medium to communicate, express, and understand their world.
This project highlights the continuity of human creativity, emphasizing that the act of creation is not just a part of our past, but an essential part of our present and future. It is an ancestral part of humanity that continues to thrive in this digital age.
Dreams of forgotten caves connects with the timeless human desire to create and communicate, and see how the act of creation is a fundamental part of our shared human heritage.
Dream compositions prints below / digital collectibles here


References:

lenscapes
experiments with immersive environements / 3603D
experiments with immersive environments / 3603D
Goal: publish immersive light-playing installations for users to experience in-context
Step1) Design a lens-like objects in 3D.
Using grasshopper’s paneling tools and Rhino 3D ‘s raytraced viewport visualisation I managed to create some effects to explore their refractions.









Approach 1) render a 360 3D video and use youtube’s VR player to deliver immersive experience.
Approach 2) using Apple ARKit / Reflections are beautiful but glass material does not have refraction



Approach 3) using Snap’s LensStudio / managed to get nice screen-space reflections, but not refraction
Approach 4) using facebook/instagram Spark AR Studio / couldn’t make glass material with refraction
Approach 5) using Sketchfab’s AR visualisation / glass has nice and beautiful refractions but only in VR, not AR (not able to see the distorted reality through fake glass)
Temporary solution & compromise) place the refractive installation within a created controlled 3D environment to curate the viewer’s experience.
References
Artworks that inspired this experiment:




Deep Textures
Using Machine Learning to create unexpected materials with textures and normal data.
Results:
Browse / Download 150 textures [google drive]
Here a curated selection of specially beautiful textures and normal maps












Play / Models released at Runway
Motivation:
Having extensively used CAD & 3D software packages as part of my product designer practice, I personally find the task of creating new materials tedious and expectable, without a surprise factor. On the other and, with my playing with GANs and image-based ML tools has a discovery factor that keeps me engaged with rewards of nice findings while exploring the unknown.
So, how could we create new 3D materials using GANs?
Proof of concept:
In order to test the look & feel of ML generated 3D materials, I ran a collection of 1000 Portuguese Azulejo Tiles images through StyleGAN to generate visually similar tiles. The results are surprisingly nice, so this seems to be a good direction.
Next step was to add depth to those generated images.
3D packages can read BW data and render it as height transformation (bump map), if this is done with the same image used as texture, results are ok but not accurate, as different colours with similar saturation will show with the same height :(.
So, I had to find translation tool to identify/segment which part of the tiles are embossed or extruded to add some height detail.
To add depth to those tiles, I ran some of them through DenseDepth model, and I got some interpertations of depth as grayscale images, not accurate probably because the model is trained with spatial scenes (Indoor and outdoor), but the results were beautiful and interesting.


Approach
The initial idea is to source a dataset composed of texture images (diffuse) and their corresponding normal map (a technique used for faking the lighting of bumps and dents. Normal maps are commonly stored as regular RGB images where the RGB components correspond to the X, Y, and Z coordinates, respectively, of the surface normal).
And then ran those images through StyleGAN.
It would ideal be to have two StyleGAN's to talk to each other while learning, so they'd know which normal-map relates to which texture... But doing that is beyond my current knowledge.
A workaround could be to stitch/merge both Diffuse + Normal textures into a single image, and ran it through the StyleGAN, with the hope that it would understand that there are two different and corresponding sides of each image, and thus, generate images with both sides... for later splitting them in order to get the generated diffuse and the corresponding generated normal.
But first, I need to see if the model is good at generating diffuse texture images from a highly diverse dataset containign bricks, fur, wood, foam... (probably yes, as it did with the Azulejo, but needs to be tested).
Diffuse Texture generation
The Dataset chosen is Describable Textures Dataset (DTD) a texture database, consisting of 5640 images, organized according to a list of 47 terms (categories) inspired from human perception. There are 120 images for each category.
The results are surprisingly consistent and rich, considering that some categories have confusing textures that are not “full-frame” but appear in objects or in context. i.e: “freckles”, “hair” or “foam”.

Describable Textures Dataset (DTD)









Normal Map generation
Finding a good dataset of normal-maps has been challenging, since there's an abundance of textures for sale but a scarcity of freely accessible ones. Initially I attempted to scrape some sites containing free textures, but it required too much effort to collect few hundred textures.
A first test was done with the dataset provided by the Single-Image SVBRDF Capture with a Rendering-Aware Deep Network project.
From this [85GB zipped] dataset I cropped and isolated a subset of 2700 normal map images to feed the StyleGAN training.
Dataset: Normal Maps












StyleGAN was able to understand what makes a normal map, and it generates consistent images, with the colors correctly placed.
I then ran the generated normal maps through blender to see how they drive light within a 3D environment.
Diffuse + Normal Map single image StyleGAN training.
Now I knew that StyleGAN was capable of generating nice textures and nice normal maps independently, but I needed the normal maps to correlate to the diffuse information. Since I wasn’t able to make two stylegans talk to each other while training, I opted for composing a dataset containing the diffuse and the normal map within a single image.
This time I choose cc0textures which has a good repository of PBR textures and provides a csv information that can be used to download the desired files via wget.

Dataset: 790 images












The generated images are beautiful and they work as expected.
StyleGAN is able to understand that both sides of the images are very different and respects that when generating content.
it works! The normal maps look nice and correspond to the diffuse features.
What if?…
The diffuse images generated with the image-pairs are a bit weak and uninteresting, because the source dataset isn’t as bright and variate as the DTD. But unfortunately the DTD doesn’t have normal maps associated. :(
I want a rich diffuse texture and a corresponding normal map… 🤔
Normal map generation from source diffuse texture
I had to find a wat to turn any given image into a somehow working normal map. To do this, I tested Pix2Pix (Image-to-Image Translation with Conditional Adversarial Nets) with the image pairs composed for the previous experiment.
I trained it locally with 790 images, and after 32h of training I had some nice results:
Pix2Pix generates consistent normal maps of any given texture.
Chaining models
Workflow idea:
Diffuse from StyleGAN -> input to Pix2Pix -> generate the corresponding normal mapFirst I had to brig the Pix2Pix trained model to Runway. [following these steps].
Then I used StyleGAN’s output as Pix2Pix Input. 👍
With the help of Brannon Dorsey and following this fantastic tutorial from Daniel Shiffman, we were able to run a P5js sketch to generate randomGaussian vectors for StyleGAN, and use that output to feed Pix2Pix and generate the normal-maps.

Final tests / model selection
From all the tests, the learnings are the following:
Stylegan for textures works good - [SELECTED] - dataset = 5400 images
StyleGAN for normal maps works good, but there’s no way to link the generated maps to diffuse textures - [DISCARDED]
StyleGAN trained with a 2-in-one dataset produces nice and consistent results - but the datasets used did not produce varied and rich textures. [DISCARDED]
Pix2Pix to generate normal maps from a given diffuse texture works good. [SELECTED] - dataset = 790 image pairs
Pix2Pix trained with 10000 images produced weak results. [DISCARDED]
The final approach is: StyleGan trained with textures from the DTD dataset (5400 images) -> Pix2Pix trained with a small (790) dataset of Diffuse-Normal pairs from cc0Textures
Visualization & Interaction
I really like how runway visualises the latent space using a 2D grid to explore a multi-dimensional space of possibilities. (in resonance with some of the ideas in this article: Rethinking Design Tools in the Age of Machine Learning ).
It would be great to build a similar approach to explore the generated textures within a 3D environment.
To visualise textured 3D models on the web, I explored Three.js and other tools.
babylonjs seems the best suited for this project.:
A quick test with the textures generated from StyleGAN looks nice enough.
Trying to add the grid effect found in runway makes the thing a bit slower but interesting. The challenge is how to change the textures on-the´fly with the ones generated by StyleGAN/Pix2Pix…
After some tests and experimentations I managed to load video textures, and display them within a realtime web interface. 👍
mouse wheel/pinch= zoom
click/tap + drag / arrow keys = rotate
*doesn't seem to work with Safari desktop
Learnings & Release
The StyleGAN behaved as expeced: producing more interesting results when given a more rich and varied dataset.
Pix2Pix model has proven strong enough, but results could be better. For next iterations of this idea I should explore other models. like MUNIT or even some StyleTransfer approach.
Both checkpoints have been released and are free to use at Runway. StyleGAN-Textures + Diffuse-2-Normal
You can also download the model files here for your local use.
Thanks & next
This project has been done in about two weeks, within the Something-in-Residence program at RunwayML. Thanks.
I’ve learned a lot during this project and I’m ready to build more tools and experiments blending Design/AI/3D/Crafts and help others play with ML.
For questions, comments and collaborations, please let me know -> contact here or via twitter.
Background & Glossary
Some impressive work has been previously done in that area:
Some prints:




confusing coleopterists / 🤔🐞
breeding bugs in the latent space
breeding bugs in the latent space
A beetle generator made by machine-learning thousands of #PublicDomain illustrations.
Inspired by the stream of new Machine Learning tools being developed and made accessible and how they can be used by the creative industries, I was curious to run some visual experiments with a nice source material: zoological illustrations.
Previously I ran some test with DeepDream and StyleTransfer, but after discovering the material published at Machine Learning for Artists / @ml4a_ , I decided to experiment with the Generative Adversarial Network (GAN) approach.
Creating a Dataset
Through the Biodiversity Heritage Library, I discovered the book: Biologia Centrali-Americana :zoology, botany and archaeology, hosted at archive.org, containing fantastic #PublicDomain illustrations of beetles.








Through a combination of OpenCV and ImageMagick, I managed to extract each individual illustration and generate nicely centered square images.

















Training a GAN
Following the Lecture 6: Generative models [10/23/2018] The Neural Aesthetic @ ITP-NYU, Fall 2018 - [ Lecture 6: Generative models [10/23/2018] -> Training DCGAN-tensorflow (2:27:07) ] I managed to run DCGAN with my dataset and paying with different epochs and settings I got this sets of quasi-beetles.



Nice, but ugly as cockroaches
it was time to abandone DCGAN and try StyleGAN

Expected training times for the default configuration using Tesla V100 GPUs
Training StyleGAN
I set up a machine at PaperSpace with 1 GPU (According to NVIDIA’s repository, running StyleGan on 256px images takes over 14 days with 1 Tesla GPU) 😅
I trained it with 128px images and ran it for > 3 days, costing > €125.
Results were nice! but tiny.






Generating outputs
Since PaperSpace is expensive (useful but expensive), I moved to Google Colab [which has 12 hours of K80 GPU per run for free] to generate the outputs using this StyleGAN notebook.
Results were interesting and mesmerising, but 128px beetles are too small, so the project rested inside the fat IdeasForLater folder in my laptop for some months.

In parallel, I've been playing with Runway, a fantastic tool for creative experimentation with machine learning. And in late November 2019 the training feature was ready for beta-testing.
Training in HD
I loaded the beetle dataset and trained it at full 1024px, [on top of the FlickrHD model] and after 3000 steps the results were very nice.
From Runway, I saved the 1024px model and moved it to Google Colab to generated some HD outputs.


















In December 2019 StyleGAN 2 was released, and I was able to load the StyleGAN (1) model into this StyleGAN2 notebook and run some experiments like "Projecting images onto the generatable manifold", which finds the closest generatable image based on any input image, and explored the Beetles vs Beatles:

model released
make your own fake beetles with RunwayML -> start

1/1 edition postcards




AI Bugs a crypto-collectibles

Since there is an infinite number of potential beetles that the GAN can generate, I tested adding a coat of artificial scarcity and post some outputs at Makersplace as digital collectibles on the blockchain... 🙄🤦♂️



AI bugs as a prints
I then extracted the frames from the interpolation videos and created nicely organised grids that look fantastic as framed prints and posters, and made them available via Society6.
Framed prints available in six sizes, in a white or black frame color.
Every product is made just for you
Natural white, matte, 100% cotton rag, acid and lignin-free archival paper
Gesso coating for rich color and smooth finish
Premium shatterproof acrylic cover
Frame dimensions: 1.06" (W) x 0.625" (D)
Wire or sawtooth hanger included depending on size (does not include hanging hardware)

random
mini print
each print is unique [framed]
As custom prints (via etsy)
glossary & links

HEADFOAM
Design and test of shock-absorbing structures produced by AM to be applied to helmets used as PPE (Personal Protective Equipment) in sports as climbing, biking, skating, etc.
Shock Absorbing Structures For Sports Helmet
Head Protective Equipment Fabricated With Additive Manufacturing

Project: Design and test of shock-absorbing structures produced by AM to be applied to helmets used as PPE (Personal Protective Equipment) in sports as climbing, biking, skating, etc.
Innovation: Use of an impact-absorbing structure designed specifically for AM production.
Challenge: We believe that an inner structure of a safety helmet designed with a shock-absorbing lattice structure and produced by AM would make a better helmet.
Application: The solution PPE helmet can be used in outdoors sports as climbing or biking or skating..
Activities:
Design study on several techniques to generate lattice structures.



Dynamic Impact Tests
Test consisted in dropping 5 kg round metal object onto the test subject from a height of 1m. Test was run at the User Partner lab, equipped with testing machinery, using the 1011e 1012_MAU 1002_2W ALU_SF equipment by CKL engineering (figure 3 left). Machine measures the total impact force which is absorbed by the sample, measured in Newtons.
Test results evaluation
Helmet inner part designed with shock absorbing lattice
prototypes & tests




LaaS / Lattice as a Service


This project has received funding from the European Union’s H2020 Framework Programme for research, technological development and demonstration under grant agreement no 768775.
Project supported by AMable and I4MS, done In collaboration with: ProductosClimax S.A.
AMable [AdditiveManufacturABLE ] provides support to SMEs and mid-caps for their individual uptake of additive manufacturing. Across all technologies from plastics through polymers to metals, AMable offers services that target challenges for newcomers, enthusiasts and experts alike.
I4MS -> The EU initiative to digitalise the manufacturing industry

SheDavid
3DScan Mashup / Venus de Milo + Michelangelo’s David
3DScan Mashup
Venus de Milo + Michelangelo’s David



Sculpture / 3D Printed in StainlessSteel
Source 3D models by @Scan_The_World initiative: Venus de Milo at The Louvre, Paris / Michelangelo’s David, florence

mootioon.com
Curated stream of inspiring 3D & MotionGraphics.
mootioon -> 3D / MotionGraphics / Render / Loop / C4D -> stream
An experiment to create a custom TV channel with an endless stream of inspiring motion graphics, 3D, vfx and CGI clips.
Inspired by the weird and mesmerising short-clips that inundated MTv during the 90’s, I always wanted a TV channel full of that, so I built one.
A script continuously finds clips from several sources
OBS to streams a folder containing the clips, randomly
The site links to most of the identified artists.
The service built for fun, and it doesn’t make money.
Permutation
Generative collection, designed with code, 3D printed in Stoneware.

Generative collection, designed with code, 3D printed in Stoneware.
Pieces composed by the random combination of nine basic units, placed around a cylinder.
Each piece is unique and exists within an immense landscape of millions of possible different combinations.












Material: Stoneware
Printed by: bcn3Dceramics
Software: Rhino3D / Grasshopper
Machine: PotterBot 3D printer
Design by: Bernat Cuni
Exhibited at: Argillà Argentona - International ceramics fair









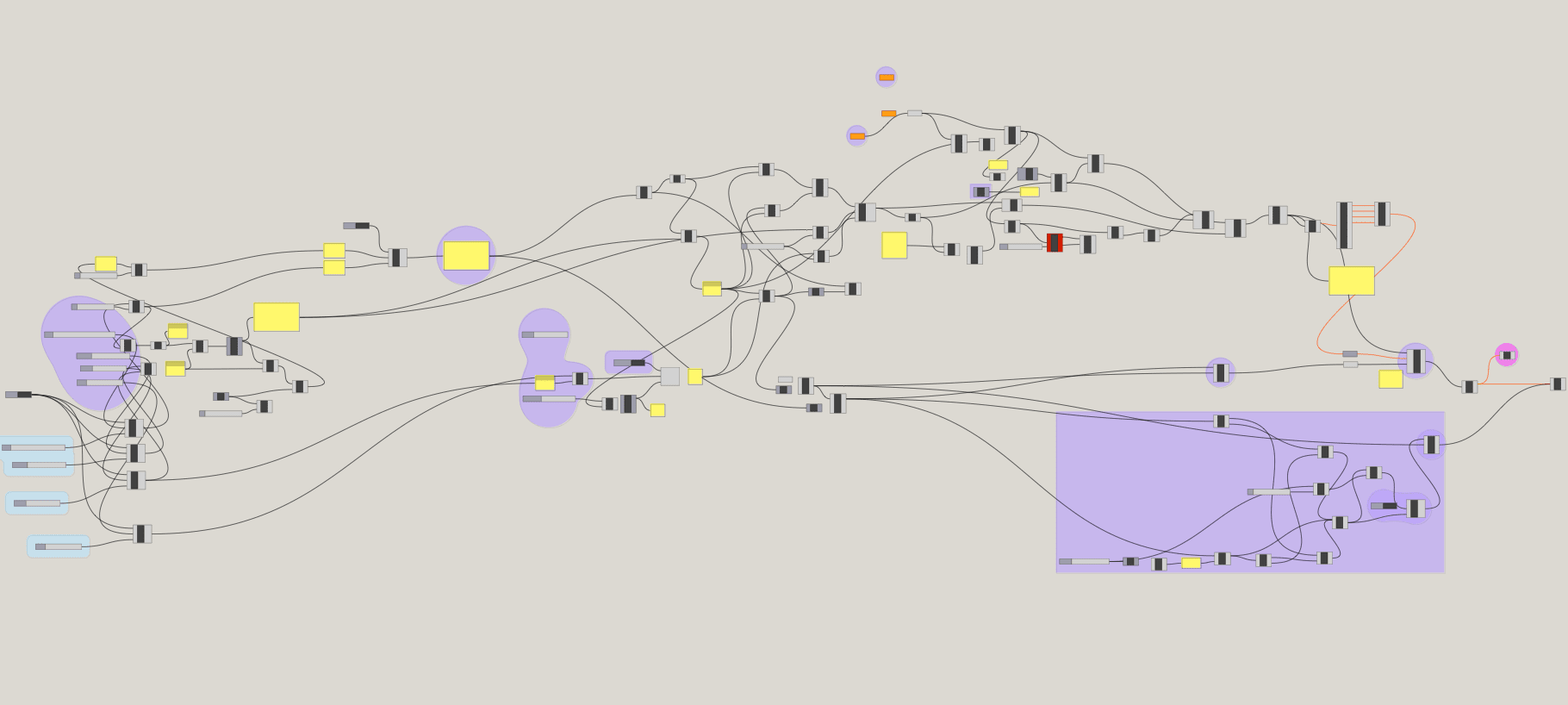
P114.3
148.791.629.670.981.130.805.037.453.479.575.340 possible combinations.

One hundred and forty eight decillion, seven hundred and ninety one nonillion, six hundred and twenty nine octillion, six hundred and seventy septillion, nine hundred and eighty one sextillion, one hundred and thirty quintillion, eight hundred and five quadrillion, and thirty seven trillion, four hundred and fifty three billion, four hundred and seventy nine million, five hundred and seventy five thousand, three hundred and forty.
P16.4
66.305.137.490.523.096 possible combinations.

sixty-six quadrillion, three hundred and five trillion, one hundred and thirty-seven billion, four hundred and ninety million, five hundred and twenty-three thousand, one hundred and four

art.faces - AI sculpts 3D faces from famous paintings
Exploration on face detection and 3D reconstruction using AI
Exploration on face detection and 3D reconstruction using the "Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression" code by Aaron S. Jackson, Adrian Bulat, Vasileios Argyriou and Georgios Tzimiropoulos.
We selected 8 Famous Paintings and let the Convolutional Neural Network (CNN) perform a direct regression of a volumetric representation of the 3D facial geometry from a single 2D image.

Mona Lisa
Leonardo da Vinci
c. 1503–06, perhaps continuing until c. 1517
Oil on poplar panel
Subject: Lisa Gherardini
77 cm × 53 cm
Musée du Louvre, Paris




Girl with a Pearl Earring
Meisje met de parel
Johannes Vermeer
c. 1665
Oil on canvas
44.5 cm × 39 cm
Mauritshuis, The Hague, Netherlands


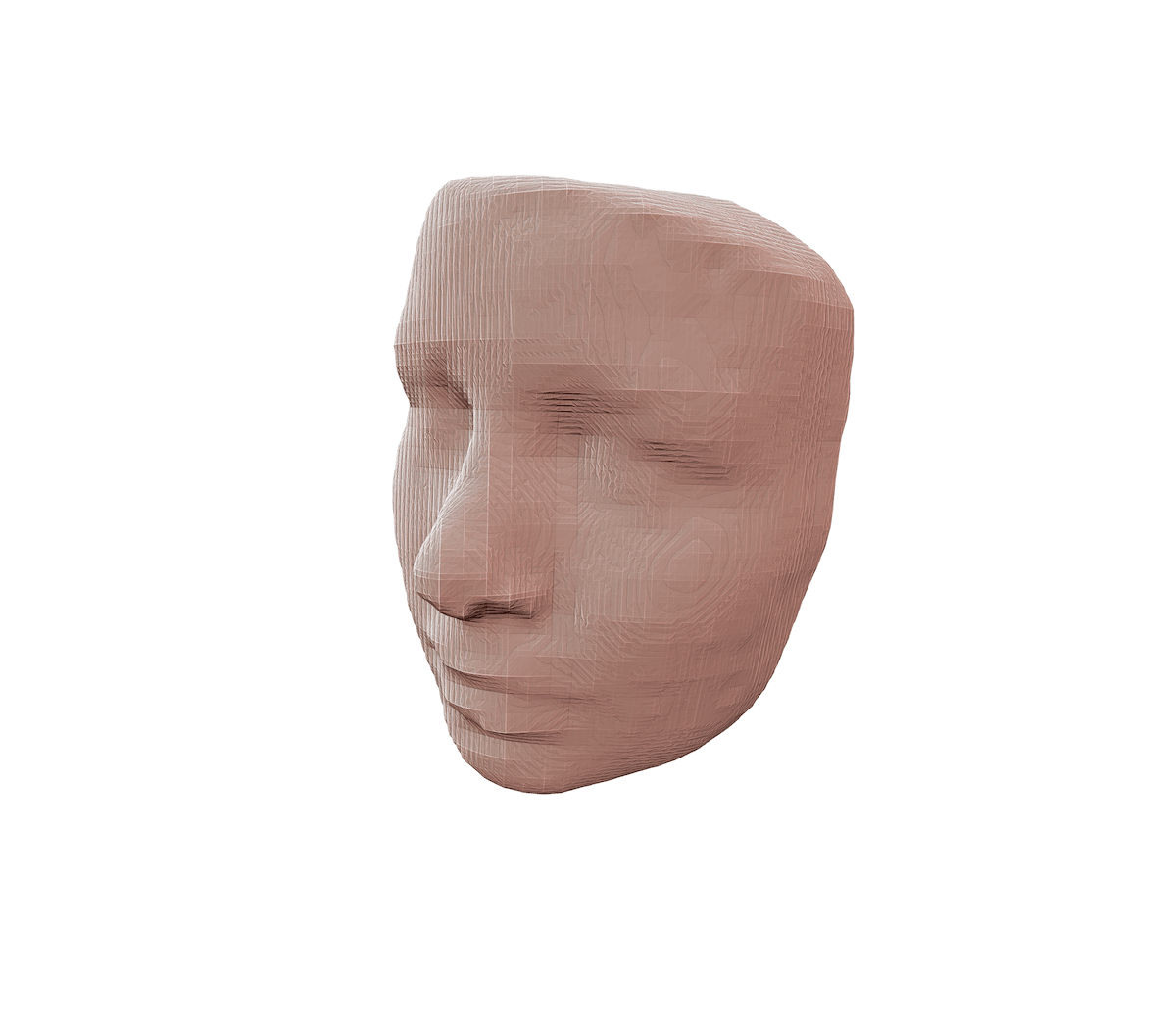

The Birth of Venus
Nascita di Venere
Sandro Botticelli,
The Birth of Venus (c. 1484-86).
Tempera on canvas.
172.5 cm × 278.9 cm.
Uffizi, Florence




Las Meninas
Diego Velázquez
1656
Oil on canvas
318 cm × 276 cm
Museo del Prado, Madrid




Self-Portrait
Vincent van Gogh
September 1889
Oil on canvas
65 × 54 cm
Musée d'Orsay, Paris.
This may have been Van Gogh's last self-portrait.




Laughing Cavalier
Frans Hals
1624
oil on canvas
83 cm × 67.3 cm
Wallace Collection, London




American Gothic
Grant Wood
1930
Oil on beaverboard
78 cm × 65.3 cm
Art Institute of Chicago







The Night Watch
Rembrandt van Rijn
1642
Oil on canvas
363 cm × 437 cm
Rijksmuseum, Amsterdam



The technology behind:
Code available on GitHub
Test your images with this demo,
This tech is fantastic and amazing, but same as with DeepFakes, it should be handled with care… Once we can generate accurate 3D representations of anyone with minimal input data, there’s the possibility to use that 3D output as digital identity theft.
As well questioned in this VentureBeat article :
So what happens when the technology further improves (which it will) and becomes accessible to marketers and brands (which it always does)? Imagine a casting call where a dozen actors are digitally and convincingly superimposed on a stand-in model prior to engaging the actors in real life.
We can imagine a scenario where videos are created using someone’s face (and body?) to make them do whatever they want, without consent.
On the other hand, AI is getting so smart, that in some cases, it doesn’t need a real input to go wild and imagine possible realities.
In this paper by NVIDIA, a generative adversarial network is able to picture imaginary celebrities.
Particularly in the 3D space, we see a huge potential for this kind of technology.

Digital Ceramics
Ceramic 3D Printing products and services for the industry & the arts
Ceramic Additive Manufacturing products and services for the Industry & the arts
Powder Binding / SLA / Paste Extrusion











