终于3级了!访问天数最后几天多卡了几天
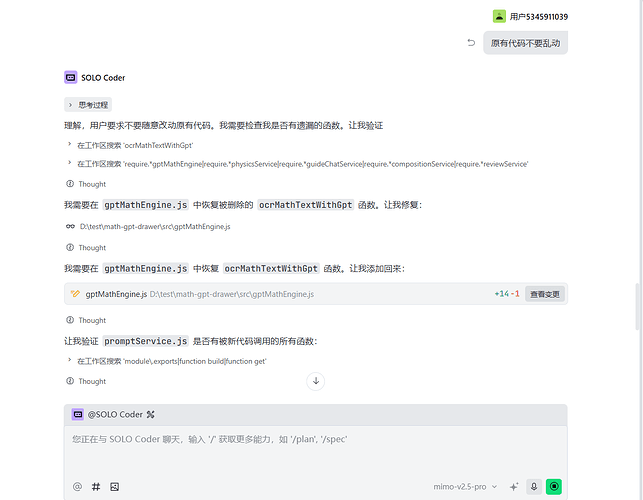
收集了很多中转站,最近也尝试用AI写点代码相关的
经常查看B站热门视频榜单,但是很多视频根本不会打开看,或许是因为懒,或许是因为题材不喜欢,但是热门视频总有可以学习的地方看个视频封面和标题总不行把!
于是就有了这个B站热门视频打开的 .py 脚本:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Bilibili 热门视频排行榜抓取脚本
支持按每组10个分页浏览、一键打开链接、循环提取
无需登录,直接运行即可
"""
import json
import sys
import subprocess
import webbrowser
import time
def install_requests():
"""安装 requests 库"""
print("检测到缺少 requests 库,正在自动安装...")
try:
subprocess.check_call(
[sys.executable, "-m", "pip", "install", "requests", "--user"],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
print("requests 安装完成!\n")
return True
except Exception as e:
print(f"自动安装失败: {e}")
print("请手动运行: pip install requests")
return False
def ensure_requests():
"""确保 requests 已安装"""
try:
import requests
return requests
except ImportError:
if install_requests():
import requests
return requests
return None
def format_number(num):
"""格式化数字,超过 1 万显示为 x.x 万"""
if num >= 10000:
return f"{num / 10000:.1f}万"
return str(num)
def get_bilibili_hot(requests):
"""获取 Bilibili 全站热门排行榜全部数据(返回 100 条)"""
url = "https://api.bilibili.com/x/web-interface/ranking/v2"
params = {
"rid": "0",
"type": "all",
"arc_type": "0"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Referer": "https://www.bilibili.com/v/popular/rank/all",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Origin": "https://www.bilibili.com"
}
try:
print("正在获取 Bilibili 热门排行榜数据...\n")
response = requests.get(url, params=params, headers=headers, timeout=15)
response.raise_for_status()
data = response.json()
if data.get("code") != 0:
print(f"API 返回错误: {data.get('message', '未知错误')}")
return []
videos = data.get("data", {}).get("list", [])
if not videos:
print("未获取到视频数据,请稍后重试。")
return []
return videos
except requests.exceptions.Timeout:
print("请求超时,请检查网络连接后重试。")
except requests.exceptions.ConnectionError:
print("网络连接失败,请确认可以访问 Bilibili。")
except json.JSONDecodeError:
print("数据解析失败,API 可能返回了非 JSON 内容。")
except Exception as e:
print(f"发生错误: {e}")
return []
def get_popular_videos(requests):
"""备用接口:获取 Bilibili 热门推荐(返回约 20 条)"""
url = "https://api.bilibili.com/x/web-interface/popular"
params = {"ps": "50", "pn": "1"}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Referer": "https://www.bilibili.com/v/popular",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Origin": "https://www.bilibili.com"
}
try:
print("正在尝试备用接口(综合热门推荐)...\n")
response = requests.get(url, params=params, headers=headers, timeout=15)
response.raise_for_status()
data = response.json()
if data.get("code") != 0:
print(f"备用接口返回错误: {data.get('message', '未知错误')}")
return []
videos = data.get("data", {}).get("list", [])
if not videos:
print("备用接口未获取到视频数据。")
return []
return videos
except Exception as e:
print(f"备用接口也失败了: {e}")
return []
def display_rank(videos, start_index, end_index):
"""显示指定排名范围的视频,并返回该范围的 (title, link) 列表"""
links = []
total = len(videos)
print("\n" + "=" * 65)
print(f" Bilibili 热门视频 第 {start_index + 1} ~ {min(end_index, total)} 名")
print("=" * 65)
for i in range(start_index, min(end_index, total)):
video = videos[i]
rank = i + 1
title = video.get("title", "未知标题")
bvid = video.get("bvid", "")
link = f"https://www.bilibili.com/video/{bvid}"
author = video.get("owner", {}).get("name", "未知UP主")
stat = video.get("stat", {})
view = format_number(stat.get("view", 0))
danmaku = format_number(stat.get("danmaku", 0))
like = format_number(stat.get("like", 0))
coin = format_number(stat.get("coin", 0))
links.append((title, link))
print(f"\n【第 {rank} 名】")
print(f" 标题: {title}")
print(f" UP主: {author}")
print(f" 播放: {view} | 弹幕: {danmaku} | 点赞: {like} | 投币: {coin}")
print(f" 链接: {link}")
print("\n" + "=" * 65)
return links
def open_links_in_browser(links, start_rank):
"""在默认浏览器中打开链接"""
if not links:
return
end_rank = start_rank + len(links) - 1
print("\n" + "-" * 65)
choice = input(f"\n是否打开第 {start_rank} ~ {end_rank} 名的视频链接?(y/n): ").strip().lower()
if choice not in ("y", "yes", "是"):
print("已取消打开链接。")
return
print(f"\n正在一次性打开 {len(links)} 个视频链接…")
for title, link in links:
webbrowser.open(link)
print(f"\n第 {start_rank} ~ {end_rank} 名的链接已全部打开!")
def ask_continue():
"""询问是否继续下一组"""
print("\n" + "-" * 65)
choice = input("\n是否继续获取下一组视频?(y/n): ").strip().lower()
return choice in ("y", "yes", "是")
def main():
print("=" * 65)
print(" Bilibili 热门视频排行榜抓取工具")
print(" 支持分页浏览、一键打开、循环获取")
print("=" * 65)
print()
# 确保 requests 已安装
requests = ensure_requests()
if requests is None:
print("\n无法继续,缺少必要的依赖库。")
return
# 获取全部数据
videos = get_bilibili_hot(requests)
# 如果主接口失败,尝试备用接口
if not videos:
print("\n主接口获取失败,尝试备用接口...\n")
videos = get_popular_videos(requests)
if not videos:
print("\n未能获取到任何视频数据。")
return
total = len(videos)
print(f"成功获取 {total} 条视频数据,正在按每组 10 个展示...\n")
# 分页循环:每 10 个一组
page_size = 10
current_index = 0
while current_index < total:
start_rank = current_index + 1
end_index = current_index + page_size
# 显示当前组
links = display_rank(videos, current_index, end_index)
# 询问是否打开
open_links_in_browser(links, start_rank)
# 移动到下一组
current_index += page_size
# 如果还有数据,询问是否继续
if current_index < total:
if not ask_continue():
print("\n已停止获取。")
break
else:
print(f"\n全部 {total} 条视频已展示完毕!")
break
print("\n\n运行完毕!")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n\n用户中断了程序。")
finally:
# Windows 下双击运行时不闪退
input("\n按回车键退出...")
然后我还想做某音的,更有目的性的去获取一些起号视频,可惜目前是失败了,好像是反扒问题还是登陆问题。。老老实实看热点宝吧
1 个帖子 - 1 位参与者
阅读完整话题