We typically follow the below steps for designing a database for an application.
- Gather the requirements (functional and data) by asking questions to the database users.
- Do a logical or conceptual design of the database. This is where ER model plays a role. It is the most used graphical representation of the conceptual design of a database.
- Physical Database Design (Like indexing) and external design (like views)
The Entity Relationship Model is a model for identifying entities (like student, car or company) to be represented in the database and representation of how those entities are related. The ER data model specifies enterprise schema that represents the overall logical structure of a database graphically.
Why Use ER Diagrams In DBMS?
- ER diagrams represent the E-R model in a database, making them easy to convert into relations (tables).
- ER diagrams provide the purpose of real-world modeling of objects which makes them intently useful.
- ER diagrams require no technical knowledge of the underlying DBMS used.
- It gives a standard solution for visualizing the data logically.
Symbols Used in ER Model
ER Model is used to model the logical view of the system from a data perspective which consists of these symbols:
- Rectangles: Rectangles represent Entities in the ER Model.
- Ellipses: Ellipses represent Attributes in the ER Model.
- Diamond: Diamonds represent Relationships among Entities.
- Lines: Lines represent attributes to entities and entity sets with other relationship types.
- Double Ellipse: Double Ellipses represent Multi-Valued Attributes.
- Double Rectangle: Double Rectangle represents a Weak Entity.

Symbols used in ER Diagram
Components of ER Diagram
ER Model consists of Entities, Attributes, and Relationships among Entities in a Database System.

Components of ER Diagram
What is Entity?
An Entity may be an object with a physical existence – a particular person, car, house, or employee – or it may be an object with a conceptual existence – a company, a job, or a university course.
What is Entity Set?
An Entity is an object of Entity Type and a set of all entities is called an entity set. For Example, E1 is an entity having Entity Type Student and the set of all students is called Entity Set. In ER diagram, Entity Type is represented as:

Entity Set
We can represent the entity set in ER Diagram but can’t represent entity in ER Diagram because entity is row and column in the relation and ER Diagram is graphical representation of data.
Types of Entity
There are two types of entity:
1. Strong Entity
A Strong Entity is a type of entity that has a key Attribute. Strong Entity does not depend on other Entity in the Schema. It has a primary key, that helps in identifying it uniquely, and it is represented by a rectangle. These are called Strong Entity Types.
2. Weak Entity
An Entity type has a key attribute that uniquely identifies each entity in the entity set. But some entity type exists for which key attributes can’t be defined. These are called Weak Entity types .
For Example, A company may store the information of dependents (Parents, Children, Spouse) of an Employee. But the dependents can’t exist without the employee. So Dependent will be a Weak Entity Type and Employee will be Identifying Entity type for Dependent, which means it is Strong Entity Type .
A weak entity type is represented by a Double Rectangle. The participation of weak entity types is always total. The relationship between the weak entity type and its identifying strong entity type is called identifying relationship and it is represented by a double diamond.

Strong Entity and Weak Entity
What is Attributes?
Attributes are the properties that define the entity type. For example, Roll_No, Name, DOB, Age, Address, and Mobile_No are the attributes that define entity type Student. In ER diagram, the attribute is represented by an oval.

Attribute
Types of Attributes
1. Key Attribute
The attribute which uniquely identifies each entity in the entity set is called the key attribute. For example, Roll_No will be unique for each student. In ER diagram, the key attribute is represented by an oval with underlying lines.

Key Attribute
2. Composite Attribute
An attribute composed of many other attributes is called a composite attribute. For example, the Address attribute of the student Entity type consists of Street, City, State, and Country. In ER diagram, the composite attribute is represented by an oval comprising of ovals.

Composite Attribute
3. Multivalued Attribute
An attribute consisting of more than one value for a given entity. For example, Phone_No (can be more than one for a given student). In ER diagram, a multivalued attribute is represented by a double oval.

Multivalued Attribute
4. Derived Attribute
An attribute that can be derived from other attributes of the entity type is known as a derived attribute. e.g.; Age (can be derived from DOB). In ER diagram, the derived attribute is represented by a dashed oval.

Derived Attribute
The Complete Entity Type Student with its Attributes can be represented as:

Entity and Attributes
Relationship Type and Relationship Set
A Relationship Type represents the association between entity types. For example, ‘Enrolled in’ is a relationship type that exists between entity type Student and Course. In ER diagram, the relationship type is represented by a diamond and connecting the entities with lines.

Entity-Relationship Set
A set of relationships of the same type is known as a relationship set. The following relationship set depicts S1 as enrolled in C2, S2 as enrolled in C1, and S3 as registered in C3.

Relationship Set
Degree of a Relationship Set
The number of different entity sets participating in a relationship set is called the degree of a relationship set.
1. Unary Relationship: When there is only ONE entity set participating in a relation, the relationship is called a unary relationship. For example, one person is married to only one person.

Unary Relationship
2. Binary Relationship: When there are TWO entities set participating in a relationship, the relationship is called a binary relationship. For example, a Student is enrolled in a Course.
Binary Relationship
3. Ternary Relationship: When there are three entity sets participating in a relationship, the relationship is called a ternary relationship.
4. N-ary Relationship: When there are n entities set participating in a relationship, the relationship is called an n-ary relationship.
What is Cardinality?
The number of times an entity of an entity set participates in a relationship set is known as cardinality . Cardinality can be of different types:
1. One-to-One: When each entity in each entity set can take part only once in the relationship, the cardinality is one-to-one. Let us assume that a male can marry one female and a female can marry one male. So the relationship will be one-to-one.
the total number of tables that can be used in this is 2.

one to one cardinality
Using Sets, it can be represented as:
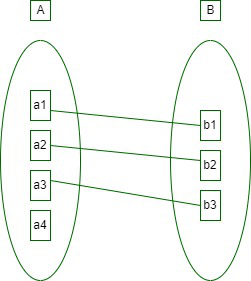
Set Representation of One-to-One
2. One-to-Many: In one-to-many mapping as well where each entity can be related to more than one entity and the total number of tables that can be used in this is 2. Let us assume that one surgeon department can accommodate many doctors. So the Cardinality will be 1 to M. It means one department has many Doctors.
total number of tables that can used is 3.

one to many cardinality
Using sets, one-to-many cardinality can be represented as:
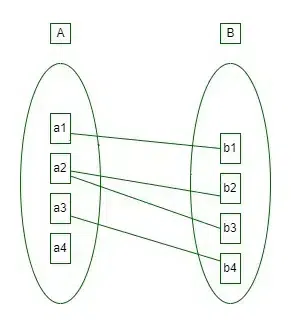
Set Representation of One-to-Many
3. Many-to-One: When entities in one entity set can take part only once in the relationship set and entities in other entity sets can take part more than once in the relationship set, cardinality is many to one. Let us assume that a student can take only one course but one course can be taken by many students. So the cardinality will be n to 1. It means that for one course there can be n students but for one student, there will be only one course.
The total number of tables that can be used in this is 3.

many to one cardinality
Using Sets, it can be represented as:
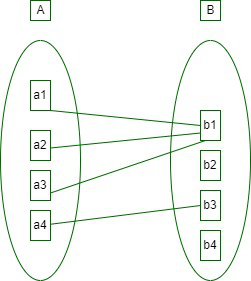
Set Representation of Many-to-One
In this case, each student is taking only 1 course but 1 course has been taken by many students.
4. Many-to-Many: When entities in all entity sets can take part more than once in the relationship cardinality is many to many. Let us assume that a student can take more than one course and one course can be taken by many students. So the relationship will be many to many.
the total number of tables that can be used in this is 3.

many to many cardinality
Using Sets, it can be represented as:

Many-to-Many Set Representation
In this example, student S1 is enrolled in C1 and C3 and Course C3 is enrolled by S1, S3, and S4. So it is many-to-many relationships.
Participation Constraint
Participation Constraint is applied to the entity participating in the relationship set.
1. Total Participation – Each entity in the entity set must participate in the relationship. If each student must enroll in a course, the participation of students will be total. Total participation is shown by a double line in the ER diagram.
2. Partial Participation – The entity in the entity set may or may NOT participate in the relationship. If some courses are not enrolled by any of the students, the participation in the course will be partial.
The diagram depicts the ‘Enrolled in’ relationship set with Student Entity set having total participation and Course Entity set having partial participation.

Total Participation and Partial Participation
Using Set, it can be represented as,
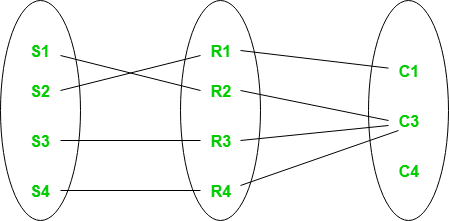
Set representation of Total Participation and Partial Participation
Every student in the Student Entity set participates in a relationship but there exists a course C4 that is not taking part in the relationship.
How to Draw ER Diagram?
- The very first step is Identifying all the Entities, and place them in a Rectangle, and labeling them accordingly.
- The next step is to identify the relationship between them and place them accordingly using the Diamond, and make sure that, Relationships are not connected to each other.
- Attach attributes to the entities properly.
- Remove redundant entities and relationships.
- Add proper colors to highlight the data present in the database.
Conclusion
An Entity-Relationship (ER) model is a way to visually represent the structure of a database. It shows how different entities (like objects or concepts) are connected and interact with each other through relationships. The model uses diagrams to represent entities as rectangles and relationships as diamonds, making it easier to design and understand databases .
Frequently Asked Questions on ER Model – FAQ’s
What is the main purpose of an ER Diagram?
ER Diagrams are used to visually represent the structure of a database, showing entities, their attributes, and relationships between them.
How do ER Diagrams help in database design?
They simplify the process of mapping out the database structure, making it easier to organize data and understand how different entities interact.
What is the difference between a Weak Entity and a Strong Entity?
A Strong Entity has a unique identifier or primary key, while a Weak Entity lacks a primary key and relies on a Strong Entity for identification.
Can ER Diagrams represent complex data relationships?
Yes, ER Diagrams can model complex relationships, including one-to-one, one-to-many, and many-to-many relationships.
Why are Participation Constraints used in ER Diagrams?
Participation Constraints indicate whether all entities must participate in a relationship or if only some may do so, helping to accurately represent real-world scenarios.
Similar Reads
DBMS Tutorial – Learn Database Management System
Database Management System (DBMS) is a software used to manage data from a database. A database is a structured collection of data that is stored in an electronic device. The data can be text, video, image or any other format.A relational database stores data in the form of tables and a NoSQL databa
7 min read
Basic of DBMS
Introduction of DBMS (Database Management System)
A database is a collection of interrelated data that helps in the efficient retrieval, insertion, and deletion of data from the database and organizes the data in the form of tables, views, schemas, reports, etc. For Example, a university database organizes the data about students, faculty, admin st
9 min read
History of DBMS
The first database management systems (DBMS) were created to handle complex data for businesses in the 1960s. These systems included Charles Bachman's Integrated Data Store (IDS) and IBM's Information Management System (IMS). Databases were first organized into tree-like structures using hierarchica
7 min read
Advantages of Database Management System
Database Management System (DBMS) is a collection of interrelated data and a set of software tools/programs that access, process, and manipulate data. It allows access, retrieval, and use of that data by considering appropriate security measures. The Database Management system (DBMS) is really usefu
6 min read
Disadvantages of DBMS
You might have encountered bulks of files/registers either at some office/school/university. The traditional file management system has been followed for managing the information or data at many organizations and by many businesses. It used to be cost-effective and easily accessible. With evolving t
9 min read
Application of DBMS
The efficient and safe management, saving and retrieval of data is made possible by the Database Management Systems. They provide strong solutions for the data management demands and are the foundation of the numerous applications used in a variety of the sectors. Recognizing the uses of DBMSs aids
5 min read
Need for DBMS
In earlier days, the databases were created directly on top of file systems. File system has many disadvantages. Disadvantages of File SystemsMemory and PerformanceLarge datasets exceed RAM, requiring frequent data transfer between memory and storage, which reduces performance.Addressing limitations
4 min read
DBMS Architecture 1-level, 2-Level, 3-Level
A Database stores a lot of critical information to access data quickly and securely. Hence it is important to select the correct architecture for efficient data management. DBMS Architecture helps users to get their requests done while connecting to the database. We choose database architecture depe
4 min read
Difference between File System and DBMS
A file system and a DBMS are two kinds of data management systems that are used in different capacities and possess different characteristics. A File System is a way of organizing files into groups and folders and then storing them in a storage device. It provides the media that stores data as well
6 min read
Entity Relationship Model
Introduction of ER Model
We typically follow the below steps for designing a database for an application. Gather the requirements (functional and data) by asking questions to the database users.Do a logical or conceptual design of the database. This is where ER model plays a role. It is the most used graphical representatio
10 min read
Structural Constraints of Relationships in ER Model
Structural constraints, within the context of Entity-Relationship (ER) modeling, specify and determine how the entities take part in the relationships and this gives an outline of how the interactions between the entities can be designed in a database. Two primary types of constraints are cardinalit
6 min read
Difference between entity, entity set and entity type
The Entity-Relationship (ER) Model is one of the primary components of Database Management Systems and is very important for designing the logical structure of databases. It helps define data, and the relationship between the data entities and it makes the system easier to visualize. This is the rea
7 min read
Difference between Strong and Weak Entity
An entity is a “thing” or “object” in the real world. An entity contains attributes, which describe that entity. So anything about which we store information is called an entity. Entities are recorded in the database and must be distinguishable, i.e., easily recognized from the group. In this articl
3 min read
Generalization, Specialization and Aggregation in ER Model
Using the ER model for bigger data creates a lot of complexity while designing a database model, So in order to minimize the complexity Generalization, Specialization, and Aggregation were introduced in the ER model. These were used for data abstraction. In which an abstraction mechanism is used to
4 min read
Recursive Relationships in ER diagrams
A relationship between two entities of a similar entity type is called a recursive relationship. Here the same entity type participates more than once in a relationship type with a different role for each instance. In other words, a relationship has always been between occurrences in two different e
4 min read
Relational Model
Introduction of Relational Model and Codd Rules in DBMS
It proposes a relational database model developed by Dr. E.F. Codd, wherein data is presented in tabular form using the concept of relations; that is, two-dimensional tables. Its other key features are as follows: Simplicity: Conveying simplicity in implementation, simplifies the operations that one
14 min read
Types of Keys in Relational Model (Candidate, Super, Primary, Alternate and Foreign)
Keys are one of the basic requirements of a relational database model. It is widely used to identify the tuples(rows) uniquely in the table. We also use keys to set up relations amongst various columns and tables of a relational database. Why do we require Keys in a DBMS?We require keys in a DBMS to
7 min read
Anomalies in Relational Model
Anomalies in the relational model refer to inconsistencies or errors that can arise when working with relational databases, specifically in the context of data insertion, deletion, and modification. There are different types of anomalies that can occur in referencing and referenced relations which c
4 min read
Mapping from ER Model to Relational Model
Converting an Entity-Relationship (ER) diagram to a Relational Model is a crucial step in database design. The ER model represents the conceptual structure of a database, while the Relational Model is a physical representation that can be directly implemented using a Relational Database Management S
7 min read
Strategies for Schema design in DBMS
There are various strategies that are considered while designing a schema. Most of these strategies follow an incremental approach that is, they must start with some schema constructs derived from the requirements and then they incrementally modify, refine, or build on them. In this article, let's d
7 min read
Relational Algebra
Introduction of Relational Algebra in DBMS
Relational Algebra is a procedural query language. Relational algebra mainly provides a theoretical foundation for relational databases and SQL. The main purpose of using Relational Algebra is to define operators that transform one or more input relations into an output relation. Given that these op
8 min read
Basic Operators in Relational Algebra
The Relational Model is a way of structuring data using relations, which are a collection of tuples that have the same attributes. Relational Algebra is a procedural query language that takes relations as input and returns relations as output. It uses a set of operators to manipulate and retrieve da
4 min read
Extended Operators in Relational Algebra
Basic idea about relational model and basic operators in Relational Algebra: Relational Model Basic Operators in Relational Algebra Extended operators are those operators which can be derived from basic operators. There are mainly three types of extended operators in Relational Algebra: JoinIntersec
6 min read
SQL Joins (Inner, Left, Right and Full Join)
SQL joins are the foundation of database management systems, enabling the combination of data from multiple tables based on relationships between columns. Joins allow efficient data retrieval, which is essential for generating meaningful observations and solving complex business queries. Understandi
6 min read
Join operation Vs Nested query in DBMS
The growth of technology and automation coupled with exponential amounts of data has led to the importance and omnipresence of databases which, simply put, are organized collections of data. Considering a naive approach, one can theoretically keep all the data in one large table, however that increa
5 min read
Tuple Relational Calculus (TRC) in DBMS
Tuple Relational Calculus (TRC) is a non-procedural query language used in relational database management systems (RDBMS) to retrieve data from tables. TRC is based on the concept of tuples, which are ordered sets of attribute values that represent a single row or record in a database table. TRC is
4 min read
Domain Relational Calculus in DBMS
Domain Relational Calculus is a non-procedural query language equivalent in power to Tuple Relational Calculus. Domain Relational Calculus provides only the description of the query but it does not provide the methods to solve it. In Domain Relational Calculus, a query is expressed as, { < x1, x2
2 min read
Normalisation
Introduction of Database Normalization
Normalization is an important process in database design that helps improve the database's efficiency, consistency, and accuracy. It makes it easier to manage and maintain the data and ensures that the database is adaptable to changing business needs. What is Database Normalization?Database normaliz
7 min read
Normal Forms in DBMS
Normalization is the process of minimizing redundancy from a relation or set of relations. Redundancy in relation may cause insertion, deletion, and update anomalies. So, it helps to minimize the redundancy in relations. Normal forms are used to eliminate or reduce redundancy in database tables. Nor
12 min read
First Normal Form (1NF)
If a table has data redundancy and is not properly normalized, then it will be difficult to handle and update the database, without facing data loss. It will also eat up extra memory space and Insertion, Update, and Deletion Anomalies are very frequent if the database is not normalized. Normalizatio
3 min read
Second Normal Form (2NF)
Normalization is a structural method whereby tables are broken down in a controlled manner with an aim of reducing data redundancy while at the same time enhancing the quality of stored data. It refers to the process of arranging the attributes and relations of a database in order to minimize data a
7 min read
Boyce-Codd Normal Form (BCNF)
Although, 3NF is an adequate normal form for relational databases, this (3NF) normal form may not remove 100% redundancy because of X−>Y functional dependency if X is not a candidate key of the given relation. This can be solved by the Boyce-Codd Normal Form (BCNF). Application of the general def
8 min read
Introduction of 4th and 5th Normal Form in DBMS
Two of the highest levels of database normalization are the fourth normal form (4NF) and the fifth normal form (5NF). Multivalued dependencies are handled by 4NF, whereas join dependencies are handled by 5NF. If two or more independent relations are kept in a single relation or we can say multivalue
5 min read
The Problem of Redundancy in Database
Redundancy means having multiple copies of the same data in the database. This problem arises when a database is not normalized. Suppose a table of student details attributes is: student ID, student name, college name, college rank, and course opted. Student_ID Name Contact College Course Rank 100Hi
6 min read
Database Management System | Dependency Preserving Decomposition
Dependency Preservation: A Decomposition D = { R1, R2, R3...Rn } of R is dependency preserving wrt a set F of Functional dependency if (F1 ? F2 ? … ? Fm)+ = F+. Consider a relation R R ---> F{...with some functional dependency(FD)....} R is decomposed or divided into R1 with FD { f1 } and R2 with
4 min read
Lossless Decomposition in DBMS
The original relation and relation reconstructed from joining decomposed relations must contain the same number of tuples if the number is increased or decreased then it is Lossy Join decomposition. Lossless join decomposition ensures that never get the situation where spurious tuples are generated
5 min read
Lossless Join and Dependency Preserving Decomposition
Decomposition of a relation is done when a relation in a relational model is not in appropriate normal form. Relation R is decomposed into two or more relations if decomposition is lossless join as well as dependency preserving. Lossless Join DecompositionIf we decompose a relation R into relations
4 min read
Denormalization in Databases
Denormalization is used to alter the structure of a database. Denormalization focuses on adding redundancy which means combining multiple tables so that execute queries quickly. In this article, we’ll explore Denormalization and how it impacts database design. What is Denormalization in Databases?De
5 min read
Transactions and Concurrency Control
Concurrency Control in DBMS
Concurrency control is a very important concept of DBMS which ensures the simultaneous execution or manipulation of data by several processes or user without resulting in data inconsistency. Concurrency Control deals with interleaved execution of more than one transaction. What is Transaction? A tra
13 min read
ACID Properties in DBMS
This article is based on the concept of ACID properties in DBMS that are necessary for maintaining data consistency, integrity, and reliability while performing transactions in the database. Let's explore them. A transaction is a single logical unit of work that accesses and possibly modifies the co
7 min read
Implementation of Locking in DBMS
Locking protocols are used in database management systems as a means of concurrency control. Multiple transactions may request a lock on a data item simultaneously. Hence, we require a mechanism to manage the locking requests made by transactions. Such a mechanism is called a Lock Manager. It relies
5 min read
Lock Based Concurrency Control Protocol in DBMS
In a database management system (DBMS), lock-based concurrency control (BCC) is used to control the access of multiple transactions to the same data item. This protocol helps to maintain data consistency and integrity across multiple users. In the protocol, transactions gain locks on data items to c
6 min read
Graph Based Concurrency Control Protocol in DBMS
Graph-based concurrency control protocols are used in database management systems (DBMS) to ensure that concurrent transactions do not interfere with each other and maintain the consistency of the database. In graph-based concurrency control, transactions are represented as nodes in a graph, and the
4 min read
Two Phase Locking Protocol
Pre-Requisite: Concurrency Control Protocol, Lock-based Protocol. Now, recalling where we last left off, there are two types of Locks available Shared S(a) and Exclusive X(a). Implementing this lock system without any restrictions gives us the Simple Lock-based protocol (or Binary Locking), but it h
4 min read
Multiple Granularity Locking in DBMS
The various Concurrency Control schemes have used different methods and every individual Data item is the unit on which synchronization is performed. A certain drawback of this technique is if a transaction Ti needs to access the entire database, and a locking protocol is used, then Ti must lock eac
5 min read
Polygraph to check View Serializability in DBMS
Prerequisite - Concurrency Control -Introduction, Conflict Serializability, Transaction Isolation Levels in DBMS Serializability: If any transaction (non-serial) produces an outcome that is equal to the outcome of that schedule's transaction executed serially then we can call that transaction schedu
6 min read
Log based Recovery in DBMS
The atomicity property of DBMS states that either all the operations of transactions must be performed or none. The modifications done by an aborted transaction should not be visible to the database and the modifications done by the committed transaction should be visible. To achieve our goal of ato
7 min read
Timestamp based Concurrency Control
Timestamp-based concurrency control is a method used in database systems to ensure that transactions are executed safely and consistently without conflicts, even when multiple transactions are being processed simultaneously. This approach relies on timestamps to manage and coordinate the execution o
5 min read
Dirty Read in SQL
Pre-Requisite - Types of Schedules, Transaction Isolation Levels in DBMS A Dirty Read in SQL occurs when a transaction reads data that has been modified by another transaction, but not yet committed. In other words, a transaction reads uncommitted data from another transaction, which can lead to inc
6 min read
Types of Schedules in DBMS
Schedule, as the name suggests, is a process of lining the transactions and executing them one by one. When there are multiple transactions that are running in a concurrent manner and the order of operation is needed to be set so that the operations do not overlap each other, Scheduling is brought i
7 min read
Conflict Serializability in DBMS
As discussed in Concurrency control, serial schedules have less resource utilization and low throughput. To improve it, two or more transactions are run concurrently. However, concurrency of transactions may lead to inconsistency in the database. To avoid this, we need to check whether these concurr
5 min read
Condition of schedules to View-equivalent
In a database system, a schedule is a sequence of operations (such as read and write operations) performed by transactions in the system. Two schedules are view-equivalent if they produce the same set of results when executed against the same database state. A schedule S1 is said to be view-equivale
3 min read
Recoverability in DBMS
Recoverability is a property of database systems that ensures that, in the event of a failure or error, the system can recover the database to a consistent state. Recoverability guarantees that all committed transactions are durable and that their effects are permanently stored in the database, whil
6 min read
Precedence Graph for Testing Conflict Serializability in DBMS
A Precedence Graph or Serialization Graph is used commonly to test the Conflict Serializability of a schedule. It is a directed Graph (V, E) consisting of a set of nodes V = {T1, T2, T3..........Tn} and a set of directed edges E = {e1, e2, e3..................em}. The graph contains one node for eac
6 min read
Database Recovery Techniques in DBMS
Database Systems like any other computer system, are subject to failures but the data stored in them must be available as and when required. When a database fails it must possess the facilities for fast recovery. It must also have atomicity i.e. either transactions are completed successfully and com
11 min read
Starvation in DBMS
Starvation or Livelock is the situation when a transaction has to wait for an indefinite period of time to acquire a lock. Reasons for Starvation:If the waiting scheme for locked items is unfair. ( priority queue )Victim selection (the same transaction is selected as a victim repeatedly )Resource le
5 min read
Deadlock in DBMS
In database management systems (DBMS) a deadlock occurs when two or more transactions are unable to the proceed because each transaction is waiting for the other to the release locks on resources. This situation creates a cycle of the dependencies where no transaction can continue leading to the sta
10 min read
Types of Schedules based Recoverability in DBMS
In this article, we are going to deal with the types of Schedules based on the Recoverability in Database Management Systems (DBMS). Generally, there are three types of schedules given as follows: Schedules Based on RecoverabilityRecoverable Schedule: A schedule is recoverable if it allows for the r
5 min read
Why recovery is needed in DBMS
Basically, whenever a transaction is submitted to a DBMS for execution, the operating system is responsible for making sure or to be confirmed that all the operations which need to be performed in the transaction have been completed successfully and their effect is either recorded in the database or
6 min read
Indexing, B and B+ trees
Indexing in Databases - Set 1
Indexing improves database performance by minimizing the number of disc visits required to fulfill a query. It is a data structure technique used to locate and quickly access data in databases. Several database fields are used to generate indexes. The main key or candidate key of the table is duplic
9 min read
Introduction of B-Tree
The limitations of traditional binary search trees can be frustrating. Meet the B-Tree, the multi-talented data structure that can handle massive amounts of data with ease. When it comes to storing and searching large amounts of data, traditional binary search trees can become impractical due to the
15+ min read
Insert Operation in B-Tree
In the previous post, we introduced B-Tree. We also discussed search() and traverse() functions. In this post, insert() operation is discussed. A new key is always inserted at the leaf node. Let the key to be inserted be k. Like BST, we start from the root and traverse down till we reach a leaf node
15+ min read
Delete Operation in B-Tree
Pre-Requisite: B-Tree | Set 1 (Introduction), B-Tree | Set 2 (Insert) B Trees is a type of data structure commonly known as a Balanced Tree that stores multiple data items very easily. B Trees are one of the most useful data structures that provide ordered access to the data in the database. In this
15+ min read
Introduction of B+ Tree
B + Tree is a variation of the B-tree data structure. In a B + tree, data pointers are stored only at the leaf nodes of the tree. In a B+ tree structure of a leaf node differs from the structure of internal nodes. The leaf nodes have an entry for every value of the search field, along with a data po
8 min read
Bitmap Indexing in DBMS
Bitmap Indexing is a data indexing technique used in database management systems (DBMS) to improve the performance of read-only queries that involve large datasets. It involves creating a bitmap index, which is a data structure that represents the presence or absence of data values in a table or col
8 min read
Inverted Index
An Inverted Index is a data structure used in information retrieval systems to efficiently retrieve documents or web pages containing a specific term or set of terms. In an inverted index, the index is organized by terms (words), and each term points to a list of documents or web pages that contain
7 min read
Difference between Inverted Index and Forward Index
Inverted Index It is a data structure that stores mapping from words to documents or set of documents i.e. directs you from word to document.Steps to build Inverted index are:Fetch the document and gather all the words.Check for each word, if it is present then add reference of document to index els
2 min read
SQL Queries on Clustered and Non-Clustered Indexes
Indexes in SQL play a pivotal role in enhancing database performance by enabling efficient data retrieval without scanning the entire table. The two primary types of indexes Clustered Index and Non-Clustered Index serve distinct purposes in optimizing query performance. In this article, we will expl
7 min read
DBMS Interview questions and Last minute notes
DBMS GATE Previous Year Questions
Database Management System - GATE CSE Previous Year Questions
Solving GATE Previous Year's Questions (PYQs) not only clears the concepts but also helps to gain flexibility, speed, accuracy, and understanding of the level of questions generally asked in the GATE exam, and that eventually helps you to gain good marks in the examination. Previous Year Questions h
5 min read
Database Management Systems | Set 2
Following Questions have been asked in GATE 2012 exam. 1) Which of the following statements are TRUE about an SQL query? P: An SQL query can contain a HAVING clause even if it does not a GROUP BY clause Q: An SQL query can contain a HAVING clause only if it has a GROUP BY clause R: All attributes us
4 min read
Database Management Systems | Set 3
Following Questions have been asked in GATE 2012 exam. 1) Consider the following transactions with data items P and Q initialized to zero: T1: read (P) ; read (Q) ; if P = 0 then Q : = Q + 1 ; write (Q) ; T2: read (Q) ; read (P) ; if Q = 0 then P : = P + 1 ; write (P) ; Any non-serial interleaving o
3 min read
Database Management Systems | Set 4
Following Questions have been asked in GATE 2011 exam. 1. Consider a relational table with a single record for each registered student with the following attributes. 1. Registration_Number:< Unique registration number for each registered student 2. UID: Unique Identity number, unique at the natio
4 min read
Database Management Systems | Set 5
Following Questions have been asked in GATE CS 2010 exam. 1) A relational schema for a train reservation database is given below. Passenger (pid, pname, age) Reservation (pid, class, tid) Table: Passenger pid pname age ----------------- 0 Sachin 65 1 Rahul 66 2 Sourav 67 3 Anil 69 Table : Reservatio
4 min read
Database Management Systems | Set 6
Following questions have been asked in GATE 2009 CS exam. 1) Consider two transactions T1 and T2, and four schedules S1, S2, S3, S4 of T1 and T2 as given below: T1 = R1[X] W1[X] W1[Y] T2 = R2[X] R2[Y] W2[Y] S1 = R1[X] R2[X] R2[Y] W1[X] W1[Y] W2[Y] S2 = R1[X] R2[X] R2[Y] W1[X] W2[Y] W1[Y] S3 = R1[X]
4 min read
Database Management Systems | Set 7
Following questions have been asked in GATE 2008 CS exam. 1) Let R and S be two relations with the following schema R (P,Q,R1,R2,R3) S (P,Q,S1,S2) Where {P, Q} is the key for both schemas. Which of the following queries are equivalent? (A) Only I and II (B) Only I and III (C) Only I, II and III (D)
3 min read
Database Management Systems | Set 8
Following questions have been asked in GATE 2005 CS exam. 1) Which one of the following statements about normal forms is FALSE? (a) BCNF is stricter than 3NF (b) Lossless, dependency-preserving decomposition into 3NF is always possible (c) Lossless, dependency-preserving decomposition into BCNF is a
3 min read